Перетворення звуку на текст¶
Нове в версії 21.04.0.
Попередження
Перетворення мовлення у текст не працює у версії 21.04.2 через проблеми із програмним інтерфейсом Vosk. Скористайтеся версією 21.04.1 або 21.04.3 чи новішими версіями.
Встановлення Python¶
На вашому комп’ютері має бути встановлено Python 3 (подробиці для Linux і Windows наведено нижче). Після встановлення Python виконайте ці кроки, щоб розташувати Python у віртуальному середовищі (після цього Python буде скопійовано до теки venv)
Вилучення Python
Щоб вилучити встановлений пакунок venv перейдіть до пункту і натисніть кнопку Вилучити venv.
У результаті програма повністю вилучить теку venv із усіма встановленими пакунками. Зауважте, що це не призведе до вилучення отриманих моделей (vosk/whisper), які після цього можуть продовжити займати певне місце на диску
Linux¶
У більшості дистрибутивів Linux до типового комплекту програм включено Python. Ви можете перевірити, чи це так за допомогою команди python3 -V, відданої у терміналі. Якщо Python не встановлено, ви можете знайти безліч інструкцій з його встановлення в інтернеті.
Windows¶
Пакунки для встановлення Python можна отримати тут: https://www.python.org/downloads/.
Рушії озвучення¶
Щоб встановити рушії розпізнавання мовлення, скористайтеся пунктом .
VOSK¶
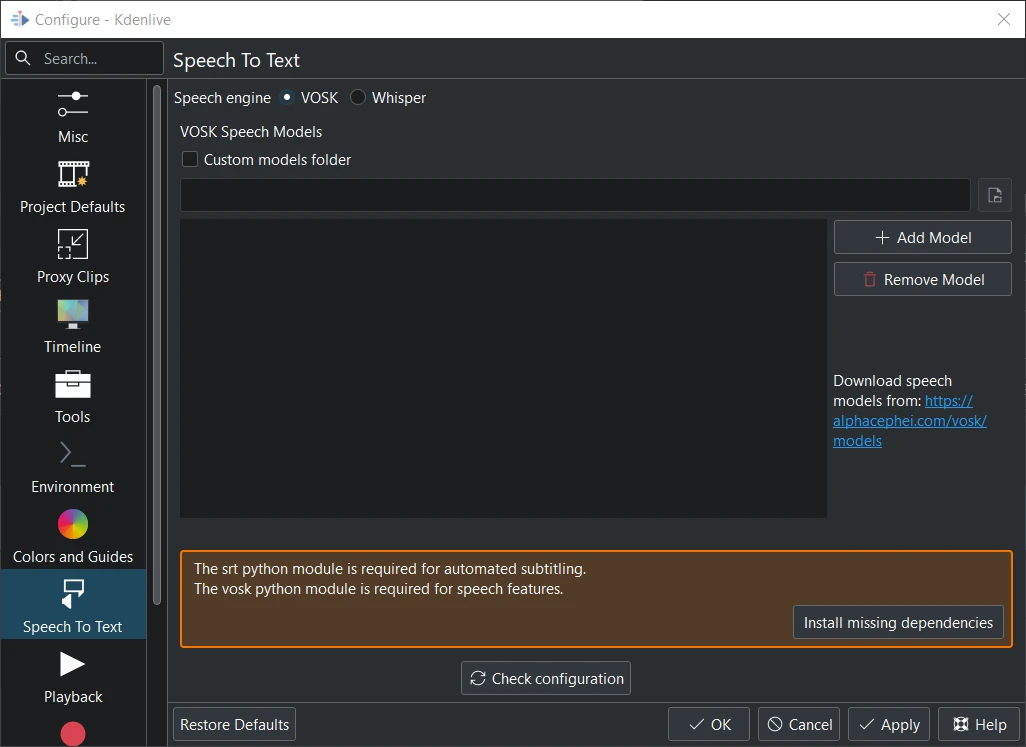
Vosk не встановлено¶
Якщо ви перший раз перемикаєтеся на VOSK, вам доведеться спочатку встановити пропущені залежності.
Шлях, куди встановлено VOSK:
Linux:
~/.local/share/kdenlive/venv/LibWindows:
%LocalAppData%\kdenlive\venv\Lib
Якщо вами було встановлено VOSK у якійсь із попередніх версій Kdenlive, а у новій версії вибрано теку venv для Python, ви можете вилучити встановлені бібліотеки VOSK за допомогою такої команди у консолі: pip uninstall vosk srt
Встановлення даних мови¶
Перейдіть і виберіть рушій озвучення VOSK.
Натисніть посилання для отримання моделі мови.

Перетягніть пункт мови, яка вам потрібна, зі сторінки отримання пакунків vosk-model у вікно моделей — програма виконає автоматичне отримання і розпакування даних.

Якщо виникають проблеми або ви хочете пошукати оновлення, натисніть кнопку Перевірити налаштування.
Моделі мовлення VOSK буде встановлено сюди:
Linux: ~/.local/share/kdenlive/speechmodels
Windows: %AppData%\kdenlive\speechmodels
Whisper¶
Нове в версії 23.04.
OpenAI-Whisper є модель розпізнавання мовлення для загального використання. Її натреновано на великому наборі даних різних звукових фрагментів, і вона може виконувати переклад та визначення мови.
Whisper є повільнішим за VOSK на процесорі, але є точнішими за VOSK. Whisper створює речення зі знаками пунктуації, навіть у базовому режимі.
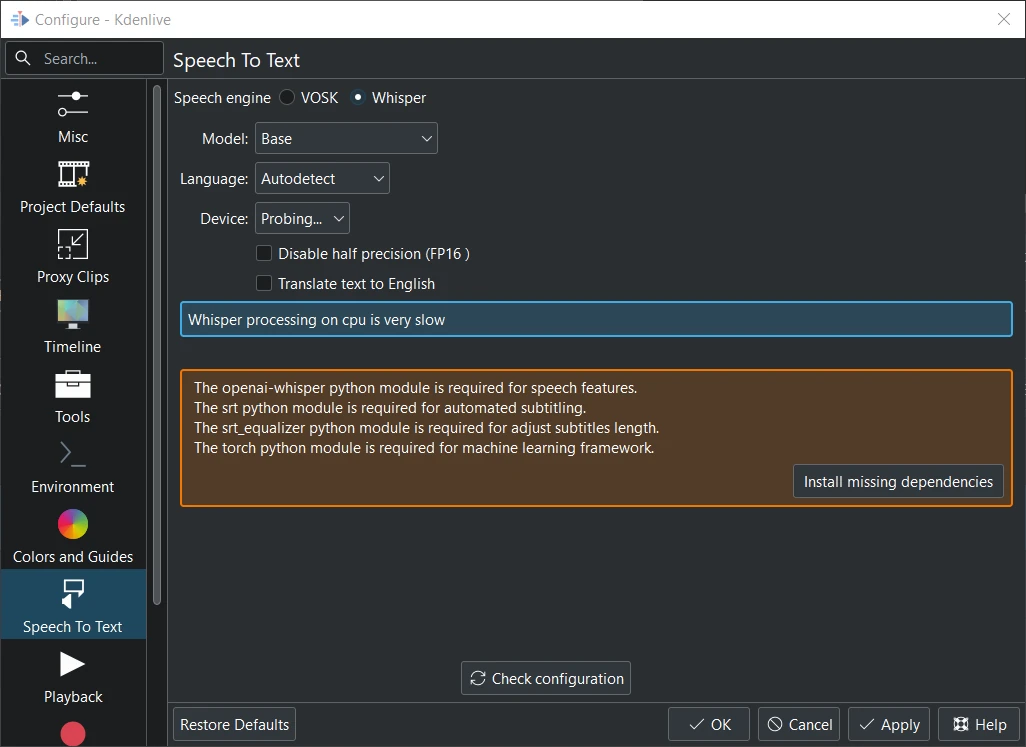
Whisper не встановлено¶
Якщо ви перший раз перемикаєтеся на Whisper, вам доведеться спочатку встановити пропущені залежності (доведеться отримати близько 2 ГБ даних).

Якщо все налаштовано правильно, ви отримаєте показане нижче вікно.
Шлях, куди встановлено Whisper:
Linux:
~/.local/share/kdenlive/venv/LibWindows:
%LocalAppData%\kdenlive\venv\Lib
Моделі мовлення Whisper зберігатимуться тут:
Linux: ~/.local/share/kdenlive/opencvmodels
Windows: %AppData%\kdenlive\opencvmodels
Модель: виберіть модель. Докладніше про це на Whisper source code page (типове значення: Базова)
Мова: виберіть мову, якщо «Автовизначення» є неправильним (типове значення: Автовизначення)
Пристрій: для підтримання сумісності, можна використовувати лише процесор.
Перекласти текст англійською: наказує програмі перекласти текст, відмінний від англійського, англійською під час розпізнавання
Виконати пошук оновлень можна натисканням кнопки Перевірити налаштування
Якщо вами вже було встановлено Whisper у якійсь із попередніх версій Kdenlive, а у новій версії вибрано теку venv для Python, ви можете вилучити старі встановлені бібліотеки Whisper за допомогою такої команди у консолі: pip uninstall openai-whisper
Розпізнавання мовлення¶
Вибір рушія озвучення¶
Нове в версії 23.04.
Виберіть пункт меню .
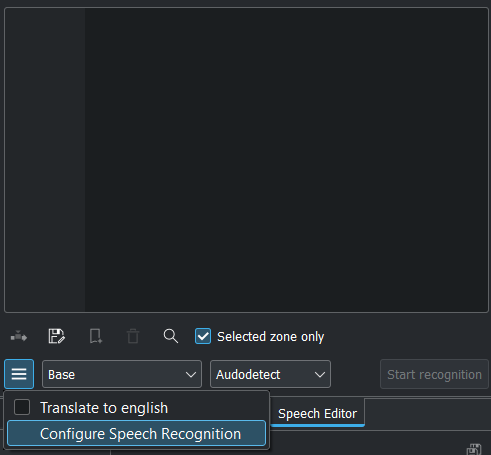
Натисніть меню-гамбургер  і виберіть пункт Налаштувати розпізнавання мовлення. У відповідь буде відкрито вікно Налаштування Перетворення звуку на текст. Виберіть рушій і натисніть кнопку Гаразд.
і виберіть пункт Налаштувати розпізнавання мовлення. У відповідь буде відкрито вікно Налаштування Перетворення звуку на текст. Виберіть рушій і натисніть кнопку Гаразд.
Пункт Перекласти текст англійською доступний лише для рушія мовлення Whisper. Наказує програмі перекласти текст, відмінний від англійського, англійською під час розпізнавання.
Створення субтитрів для розпізнавання мовлення¶

Показано з рушієм VOSK¶
Позначте на монтажному столі ділянку, де має бути розпізнано мовлення (скоригуйте розташування синьої лінії).
Натисніть піктограму Розпізнавання мовлення.
Виберіть мову.
Виберіть спосіб обробки позначеної ділянки.
Натисніть кнопку Обробити.
Субтитри буде створено і вставлено автоматично.
Примітка
У засобі створення автоматичних субтитрів поточної версії реалізовано лише ділянку на монтажному столі.
Зауваження щодо пункту 4: типова поведінка полягає в аналізі лише зони монтажного столу (усі доріжки) (синя смуга на лінійці монтажного столу). Встановіть на монтажному столі зону, аналіз якої слід виконати (скористайтеся клавішами I і O для встановлення вхідної і вихідної позицій). Якщо буде позначено пункт Позначені кліпи, програма виконає аналіз лише позначених кліпів.
Створення кліпів за розпізнаванням мовлення¶
Ця можливість корисна для інтерв’ю та іншого пов’язаного із голосовими даними матеріалу. Увімкніть пункт меню .
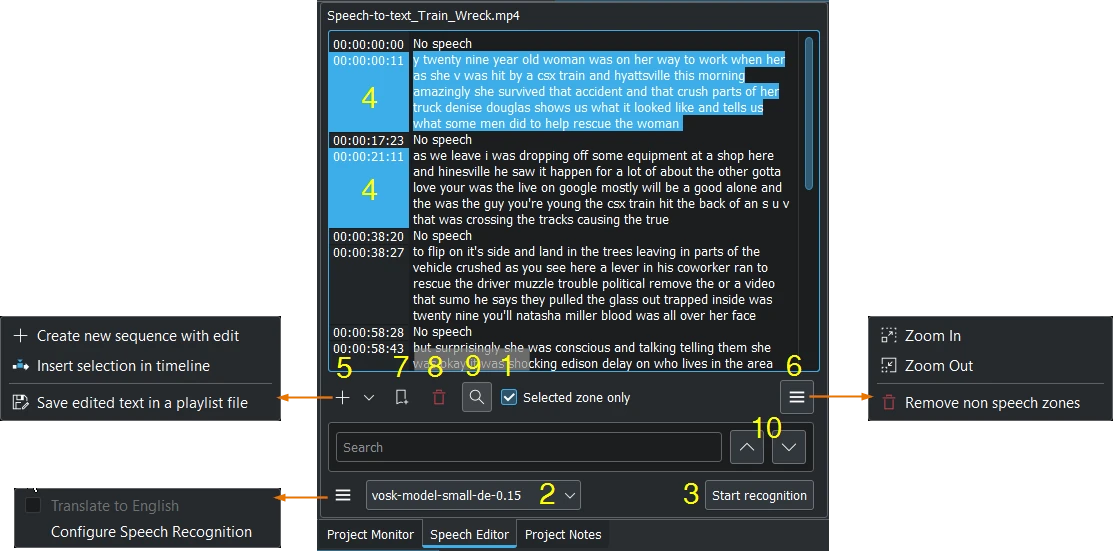
Показано з рушієм VOSK і увімкненим пошуком¶
Виберіть кліп на панелі контейнера проєкту.
Якщо потрібно, встановіть точки входу і виходу на моніторі кліпу і позначте пункт Лише позначена ділянка. У результаті буде розпізнано текст лише з вказаної ділянки.
Виберіть належну мову, якщо вибрано рушій VOSK. Або виберіть рушій Whisper натисканням пункту Налаштувати розпізнавання мовлення (див. налаштовування перетворення мовлення на текст)
Натисніть кнопку Почати розпізнавання.
Виберіть бажаний фрагмент тексту. Шляхом утримання натиснутими клавіш Ctrl або Shift можна вибрати одразу декілька фрагментів тексту.
Виберіть: Створити послідовність із редагуванням — створити послідовність із прив’язками часових позначок до тексту як окремий кліп, або Вставити позначене на монтажний стіл у позиції відтворення, або Зберегти редагований текст до файла списку відтворення для додавання пункту на панель контейнера проєкту.
Збільшити або Зменшити текст. Вилучити усі зони без голосових даних вилучає усі записи без мовлення одразу.
Додати закладку. Переходити до таких закладок на монтажному столі можна за допомогою комбінації Alt + стрілка, а редагувати закладку можна після подвійного клацання на ній.
Вилучити позначений фрагмент тексту.
Тут ви можете шукати фрагмент у тексті.
Навігація текстом вгору і вниз.
Виявлення мовчання¶
Працює лише із рушієм VOSK.
Відкрийте кліп на панелі монітора кліпу і відкрийте вікно редактора озвучення () .
Виберіть мову або встановіть мову і отримайте модель для неї.
Потім натисніть кнопку Почати розпізнавання.
Щойно цей буде зроблено, виберіть пункт 6 зі знімка вище, щоб Вилучити зони без мовлення, усі одразу. Або натисніть пункт позначки часу, де вказано «Немає озвучення» (утримуйте натиснутою клавішу Ctrl, щоб позначити декілька пунктів одразу), а потім натисніть клавішу Delete.
Повторіть дію для усіх частин, які ви хочете вилучити, включно із частинами, де хтось говорить щось, що не слід включати до остаточного варіанта.
Коли завершите, переконайтеся, що не позначено пункт Лише позначена зона, натисніть кнопку Зберегти редагований текст до файла списку відтворення (над точкою 5), і за декілька секунд на панель контейнера проєкту буде доданого новий список відтворення без проміжків з мовчанням та без небажаного тексту.