Veu a text¶
Aquesta secció s'utilitza per a configurar la funció veu a text del Kdenlive i per a gestionar els diversos models dels dos motors VOSK i Whisper.
Avís
La veu al text no funciona amb la versió 21.04.2 a causa de problemes en la API del Vosk. Utilitzeu la versió 21.04.1 o 21.04.3, així com versions posteriors.
Abans que es pugui configurar i utilitzar la veu a text, s'ha d'instal·lar Python3. Un cop instal·lat Python3, és possible que vulgueu utilitzar un entorn virtual (venv) per a mantenir-lo separat del Kdenlive d'altres usos al vostre sistema.
Si heu instal·lat el Python3 ja podeu anar directe a la pàgina de configuració.
Instal·lació al Linux¶
En la majoria de distribucions del Linux, el Python està instal·lat de manera predeterminada. Podeu comprovar si aquest és el cas del sistema executant python3 --version en un terminal. Els següents són els passos bàsics per a instal·lar el Python3 a l'Ubuntu. Si la vostra distribució no està basada en l'Ubuntu, consulteu la documentació específica o cerqueu a Internet les instruccions d'instal·lació.
$ sudo apt updates
$ sudo apt install python3
El paquet Python més important de tercers que potser necessiteu és pip. El Python 3.4 i posteriors inclouen pip de manera predeterminada però no fa mal comprovar-ho executant command -v pip en un terminal (algunes distribucions utilitzen pip per Python2 i pip3 per Python 3). Si falta pip, podeu instal·lar-lo amb
$ python3 -m ensurepip --upgrade
En cas de problemes, consulteu la pip installation guide.
Nota
En els paràgrafs següents, pip és el terme genèric per a totes les versions de pip, incloent pip3. Si us plau, utilitzeu l'ordre pip correcta del SO.
Instal·lació al Windows¶
Baixeu Python de la pàgina oficial Python download.
Motors de veu¶
Hi ha dos motors de veu disponibles: VOSK i Whisper. El Whisper d'OpenAI és un mòdul de reconeixement de veu per a ús general entrenat en un gran conjunt de dades d'àudio divers i és capaç de realitzar la traducció de la veu i la identificació de l'idioma.
El Whisper és més lent que el VOSK en la CPU, però és més precís que el VOSK. El Whisper crea frases amb signes de puntuació, fins i tot en el mode base.
Heu de configurar els models que han d'utilitzar aquests motors.
Suggeriment
Si esteu utilitzant la versió flatpak del Kdenlive, podeu experimentar problemes amb la instal·lació dels models de veu. L'enfocament de l'entorn aïllat del flatpak impedeix que el Kdenlive executi pip. Hi ha una solució possible utilitzant $ flatpak execute --command=/bin/bash org.kde.kdenlive i després $ python -m ensurepip seguit de $ python -m pip install -U openai-whisper torch (cortesia de Veronica Explains). La vostra experiència pot variar.
L'altra opció és seleccionar Whisper i després fer clic a Instal·la la traducció multilingüe. Això baixarà i instal·larà les dependències necessàries i farà que el Kdenlive sàpiga la ubicació de la vostra instal·lació del Python i pip. Després d'això podeu seguir les instruccions per configurar VOSK i Whisper aquí.
VOSK¶
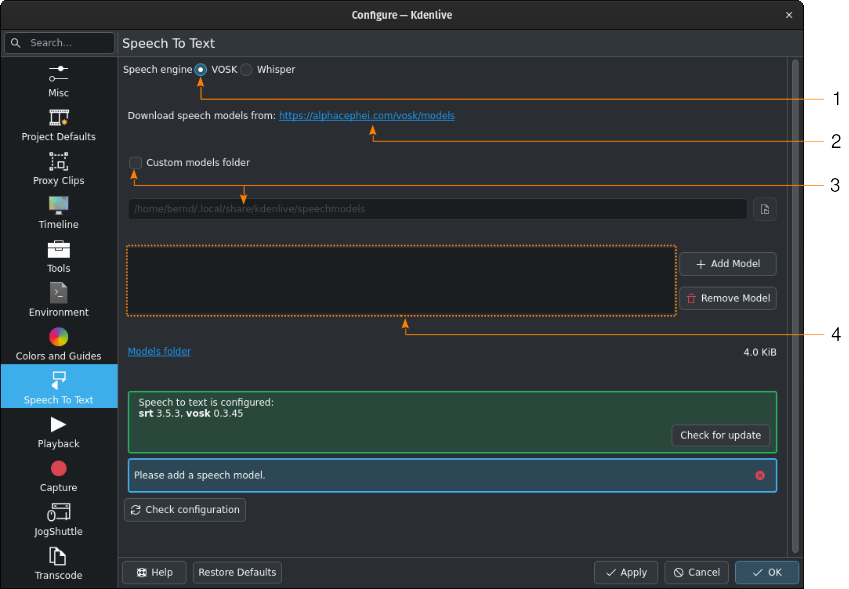
El Python està funcionant, però VOSK encara no es pot utilitzar a causa de la manca de models de veu¶
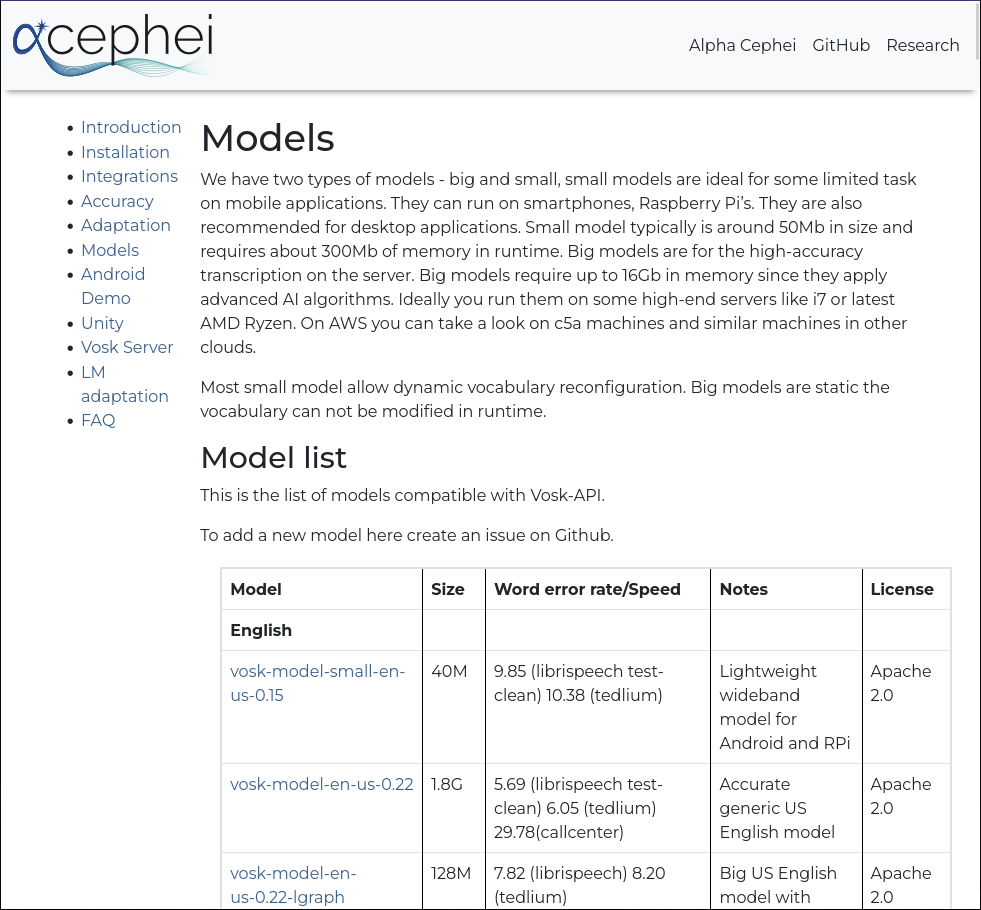
Primer heu de baixar un model de veu des de la pàgina de descàrrega alphacephei[1]. Seguiu l'enllaç (2) i baixeu els models que necessiteu.
De manera predeterminada, els models d'idioma s'instal·len a les carpetes següents:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
Si voleu utilitzar una carpeta específica, marqueu Carpeta de models personalitzats (3) i especifiqueu-la al camp de text de sota o feu clic a  Diàleg d'obrir fitxer per a navegar a la carpeta de destinació. Si utilitzeu la carpeta predeterminada, es mostrarà amb finalitats informatives al camp de text de la carpeta de models.
Diàleg d'obrir fitxer per a navegar a la carpeta de destinació. Si utilitzeu la carpeta predeterminada, es mostrarà amb finalitats informatives al camp de text de la carpeta de models.
Si heu instal·lat VOSK en una versió anterior del Kdenlive, i ara heu triat la carpeta venv per al Python, podeu suprimir les biblioteques VOSK instal·lades anteriorment utilitzant l'ordre següent en un terminal:
$ pip uninstall vosk srt
Feu clic a Afegeix un model i introduïu el camí al/s fitxer/s que heu baixat.
Feu clic a Diàleg d'obrir fitxer per a obrir el gestor de fitxers del sistema operatiu per a navegar a on heu baixat els fitxers i seleccionar el fitxer del model que voleu afegir.
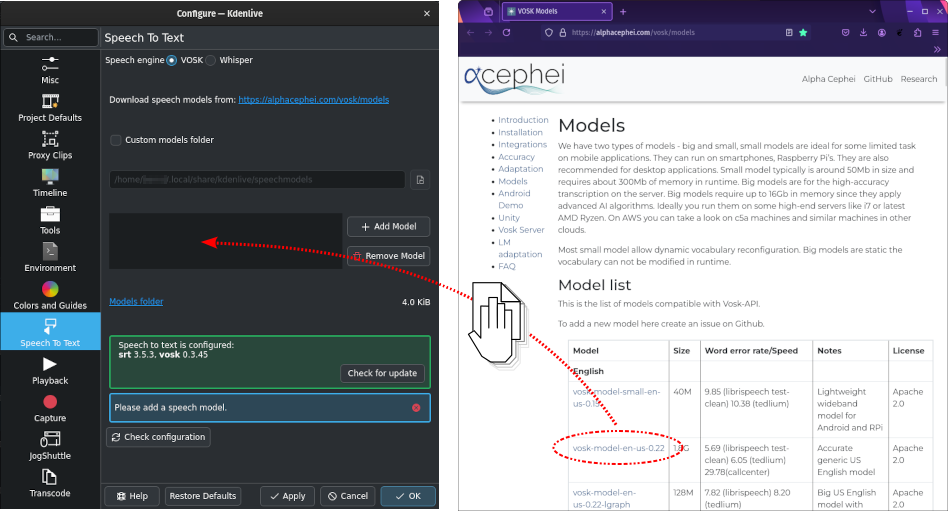
Alternativament, arrossegueu i deixeu anar el model d'idioma que voleu des de la pàgina de baixada alphacephei[1] a la finestra del model (4), i el Kdenlive us el baixarà i l'extraurà a la carpeta predeterminada o a la carpeta personalitzada que hàgiu especificat.
Nota
Els models són fitxers comprimits (.zip) i poden ser força grossos (diversos GB). Depenent de la vostra connexió a Internet, els temps de baixada poden ser llargs. Després de la descàrrega, cal extreure els fitxers que depenent de la configuració del sistema també poden trigar força temps. El Kdenlive semblarà que no respongui, però està treballant en segon pla. Tingueu paciència.
Un cop instal·lats els models, el Kdenlive mostra la mida de la carpeta dels models. Feu clic a Carpeta de models per a obrir la carpeta de models amb el gestor de fitxers del sistema operatiu.
Whisper¶

Instal·leu les dependències que manquen¶
Quan canvieu per primera vegada al Whisper haureu d'instal·lar les dependències que manquen (al voltant de 2 GB per a baixar).
Després d'això cal baixar un o més models de veu.
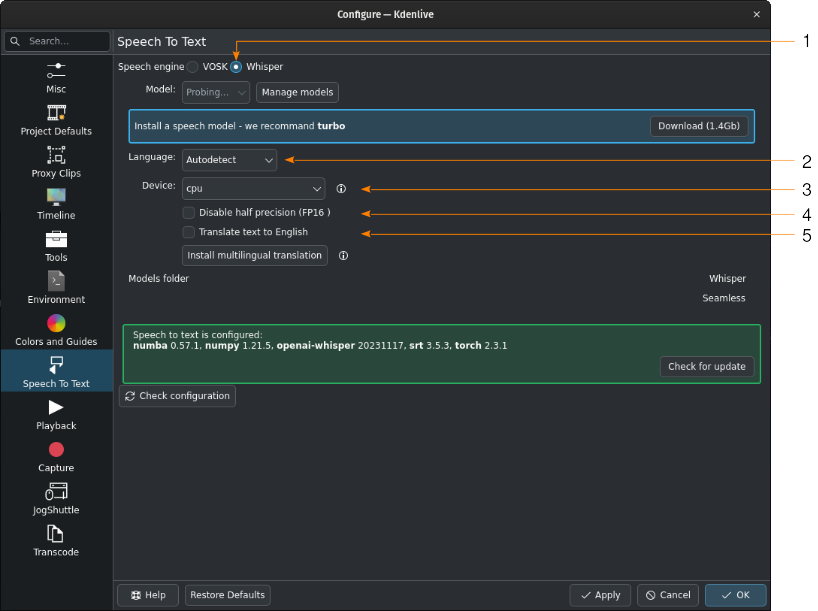
Whisper està instal·lat però no s'ha baixat cap model de veu¶
- 1:
El Whisper està seleccionat per al reconeixement de veu
- 2:
Quan es deixi a Detecta automàticament, el Kdenlive intentarà esbrinar quin idioma s'ha d'utilitzar per al reconeixement de veu. Si això dona resultats erronis, seleccioneu aquí l'idioma correcte.
- 3:
Podeu canviar entre utilitzar la CPU o la GPU per al reconeixement de veu. Es requereix una GPU que admeti CUDA per al reconeixement de veu amb la GPU.
- 4:
Només per la GPU. Quan el Kdenlive detecta una targeta gràfica NVIDIA GTX 16xx desactiva la precisió mitja (FP16) automàticament. Si teniu problemes utilitzant la GPU podeu desconnectar la precisió mitja.
- 5:
Podeu fer que Whisper tradueixi el text a l'anglès. Si necessiteu traducció a altres idiomes, heu de fer clic a Instal·la la traducció multilingüe. Això activarà SeamlessM4T[2] i baixar i instal·lar els seus models (al voltant de 10 GB de dades). El processament es farà fora de línia a partir d'aquest moment.
Feu clic a Gestiona els models o continueu amb la recomanació d'utilitzar el model turbo fent clic a Baixa (1.4GB). Més informació sobre els models disponibles es troba a la Whisper source code page.
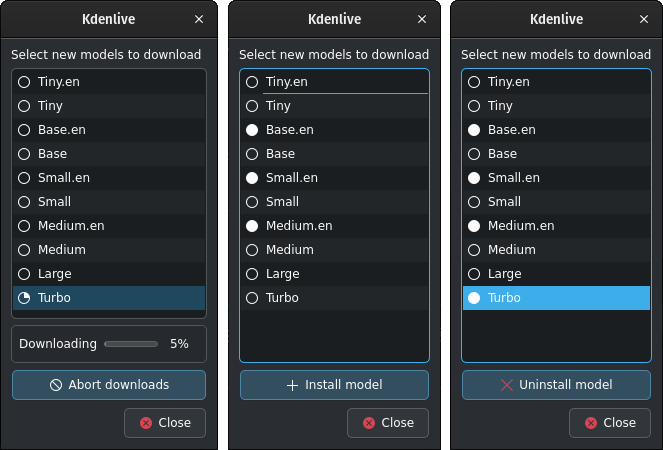
Baixada del Whisper i gestió dels models¶
El Kdenlive mostra el procés de baixada.
Els models de veu instal·lats tenen un cercle ple. Podeu suprimir-los fent clic a Desinstal·la el model
Els models disponibles tenen un cercle buit. Podeu instal·lar-los fent clic a Instal·la el model.
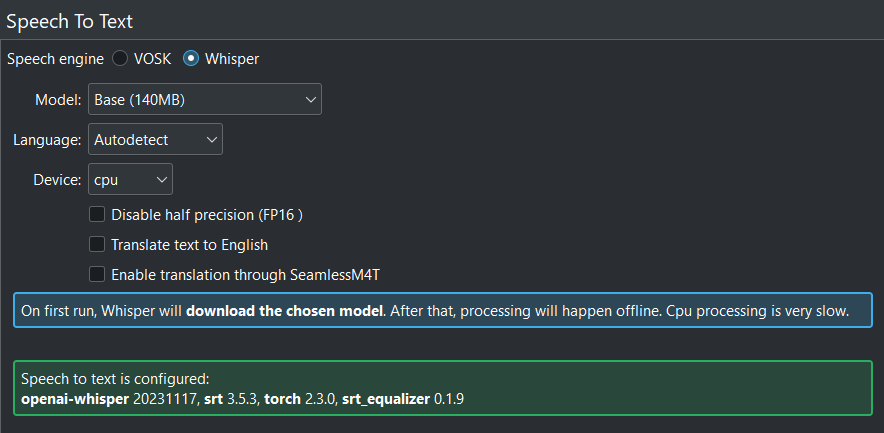
Quan tot està configurat correctament s'obté aquesta pantalla: tot verd!¶
Camí a on està instal·lat el Whisper:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
Els models de veu Whisper estan emmagatzemats aquí:
- Linux:
~/.local/share/kdenlive/opencvmodels- Windows:
%AppData%\kdenlive\opencvmodels
Per a baixar i iniciar la traducció de subtítols seguiu aquests passos.
Podeu comprovar si hi ha actualitzacions fent clic al botó Comprova la configuració
Si ja heu instal·lat el Whisper en una versió anterior del Kdenlive i ara heu triat la carpeta venv per al Python, podreu suprimir les biblioteques del Whisper instal·lades anteriorment utilitzant l'ordre següent en un terminal:
$ pip uninstall openai-whisper
Nota
Si obteniu missatges coherents durant el reconeixement de veu sobre fitxers de model que manquen, comproveu on feu clic a l'enllaç que hi ha al costat de la Carpeta de models. Si és ~/.cache a on hi ha una carpeta Whisper que conté tots els models que heu baixat, simplement copieu aquesta carpeta on el missatge d'error diu que falten (el més probable és: ~/.var/app/org.kde.kdenlive/cache)