Speech to Text¶
This section is used for setting up the Speech-to-Text feature of Kdenlive and for managing the various models for the two engines VOSK and Whisper.
Warnung
Speech to text does not work with version 21.04.2 due to Vosk API issues. Use version 21.04.1 or 21.04.3 and later versions.
Before Speech to Text can be configured and used, Python3 needs to be installed. Once Python3 is installed, you may want to use a virtual environment (venv) to keep it separate for Kdenlive from other uses on your system.
If you have installed Python3 already jump right to the configuration page.
Installation on Linux¶
On most Linux distributions Python is installed by default. You can check if that is the case for your system by running python3 --version in a terminal. The following are the basic steps for installing Python3 on Ubuntu. If your distribution is not Ubuntu-based please refer to the specific documentation or search the Internet for installation instructions.
$ sudo apt updates
$ sudo apt install python3
The crucial third-party Python package you may need is pip. Python 3.4 and later include pip by default but it does not hurt to check by running command -v pip in a terminal (some distributions use pip for Python2 and pip3 for Python 3). If pip is missing, you can install it with
$ python3 -m ensurepip --upgrade
In case of issues please refer to the pip installation guide.
Bemerkung
In the following paragraphs, pip is the generic term for all versions of pip, including pip3. Please use the correct pip command for your OS.
Installation on Windows¶
Download Python from the official Python download page.
Speech Engines¶
There are two speech engines available: VOSK and Whisper. OpenAI’s Whisper is a speech recognition module for general use trained on a large dataset of diverse audio and is capable of performing speech translation, and language identification.
Whisper is slower than VOSK on CPU, but it is more accurate than VOSK. Whisper creates sentences with punctuation marks, even in Base mode.
You need to set up the models to be used by these engines.
Hinweis
If you are using the flatpak version of Kdenlive, you may experience problems with installing the speech models. The sandbox approach of flatpak prevents kdenlive from running pip. There is a possible workaround using $ flatpak run --command=/bin/bash org.kde.kdenlive and then $ python -m ensurepip followed by $ python -m pip install -U openai-whisper torch (courtesy of Veronica Explains). Your mileage may vary.
The other option is to select Whisper and then click on Install multilingual translation. This will download and install the necessary dependencies and make Kdenlive aware of the location of your installation of Python and pip. After that you can follow the instructions for setting up VOSK and Whisper here.
VOSK¶
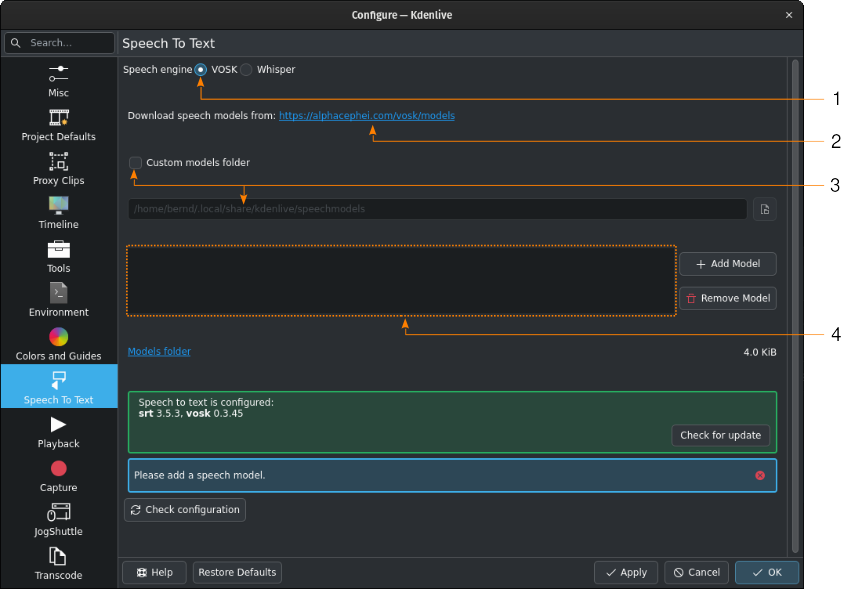
Python is working, but VOSK is not yet usable due to missing speech models¶
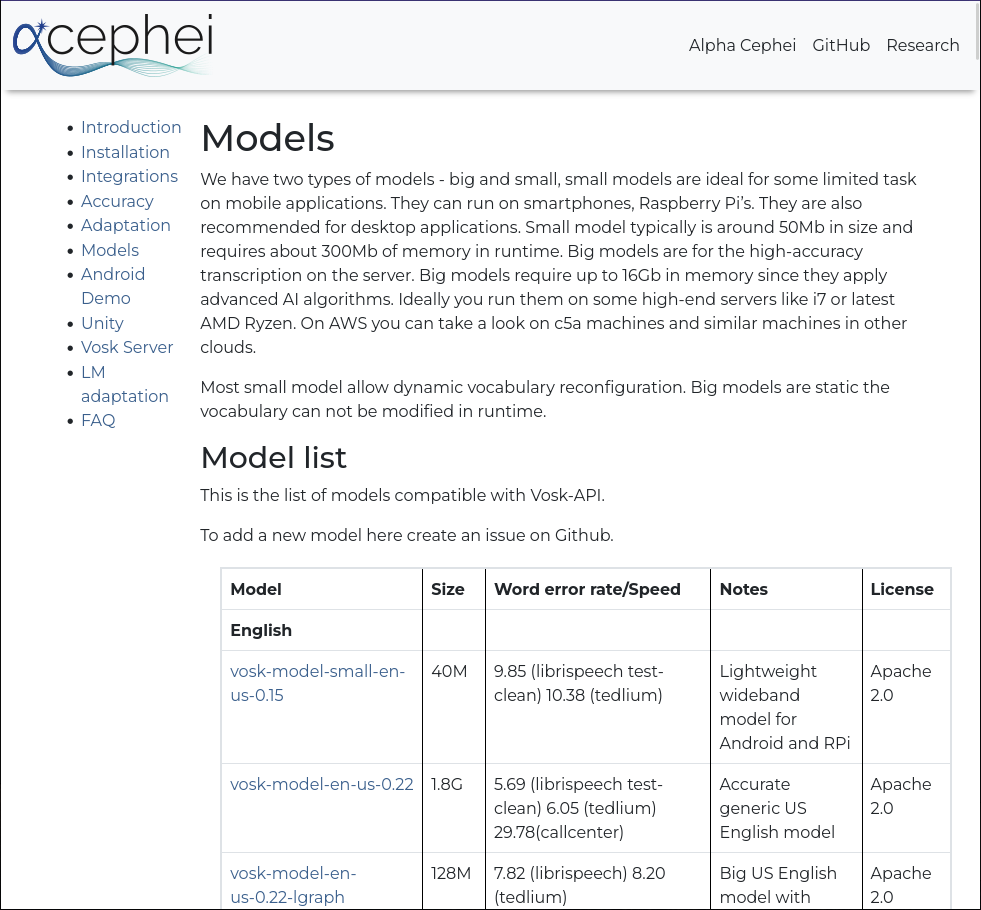
You need to download a speech model first from the alphacephei[1] download page. Follow the link (2) and download the models you need.
By default, the language models are installed into the following folders:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
If you want to use a specific folder, check Custom models folder (3) and specify it in the text field below or click on  Open file dialog to navigate to the target folder. If you use the default folder, it will be displayed for informational purposes in the models folder text field.
Open file dialog to navigate to the target folder. If you use the default folder, it will be displayed for informational purposes in the models folder text field.
If you have installed VOSK in an earlier Kdenlive version, and now you have chosen the venv folder for Python, you can delete the previously installed VOSK libraries by using the following command in a terminal:
$ pip uninstall vosk srt
Click on Add Model and enter the path to the file(s) you downloaded.
Click on Open file dialog to open the file manager of your OS to navigate to where you downloaded the files and select the model file you want to add.

Alternatively, drag & drop the language model you want from the alphacephei[1] download page to the model window (4), and Kdenlive will download and extract it for you into the default folder or the custom folder you specified.
Bemerkung
The models are compressed files (.zip) and can be several GB big. Depending on your internet connection, download times could be long. After the download, the files need to be extracted which depending on your system configuration can also take a long time. Kdenlive will appear unresponsive but is working in the background. Please be patient.
Once models have been installed, Kdenlive displays the size of the model folder. Click on Models folder to open the models folder with the file manager of your OS.
Whisper¶

Install missing dependencies¶
When you switch to Whisper for the first time you have to install the missing dependencies (about 2GB to download).
After that you need to download one or more speech models.
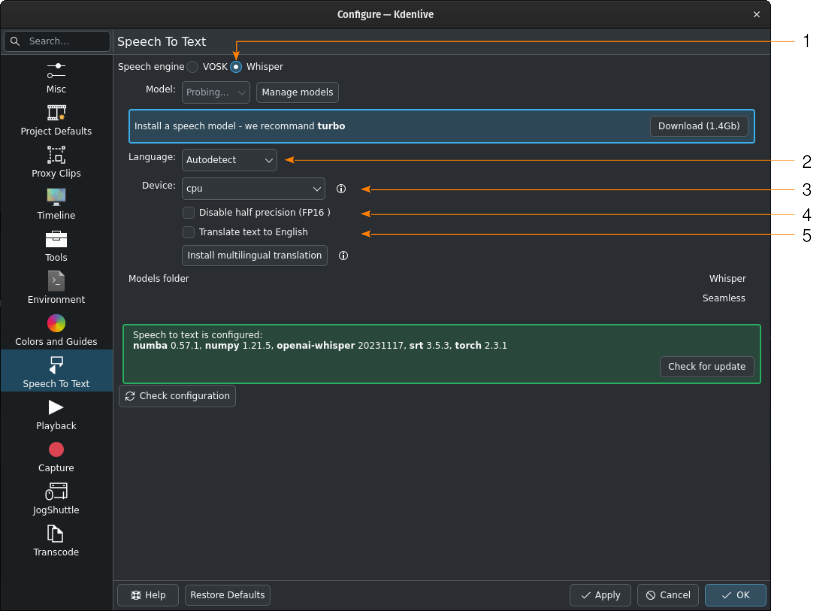
Whisper is installed but no speech model has been downloaded¶
- 1:
Whisper is selected for speech recognition
- 2:
When left at Autodetect, Kdenlive will try to figure out which language to use for speech recognition. If this gives the wrong results, select the correct language here.
- 3:
You can switch between using the CPU or your GPU for speech recognition. A GPU supporting CUDA is required for GPU speech recognition.
- 4:
Only for GPU. When Kdenlive detects a NVIDIA GTX 16xx graphic card it disables half precision (FP16) automatically. If you have issues with using GPU you can switch off half precision.
- 5:
You can have Whisper translate the text to English. If you need translation to other languages, you need to click on Install multilingual translation. This will enable SeamlessM4T[2] and download and install its models (around 10GB of data). Processing will happen offline from then on.
Click on Manage models or go with the recommendation of using the turbo model by clicking on Download (1.4GB). More information about the available models is on the Whisper source code page.
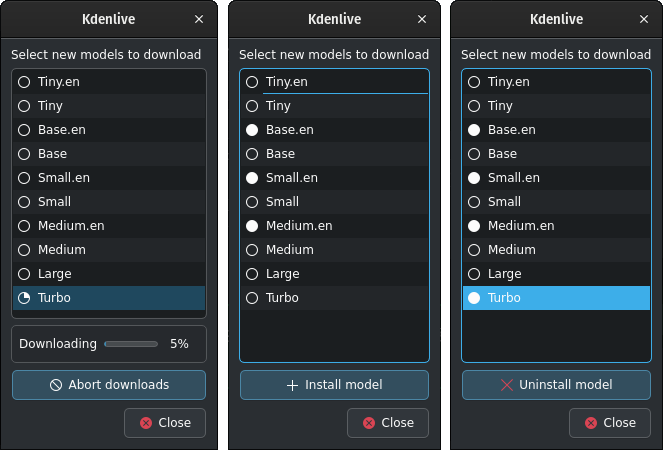
Whisper download and manage models¶
Kdenlive shows the download process.
Installed speech models have a solid circle. You can delete them by clicking on Uninstall model
Available models have a hollow circle. You can install them by clicking on Install model.
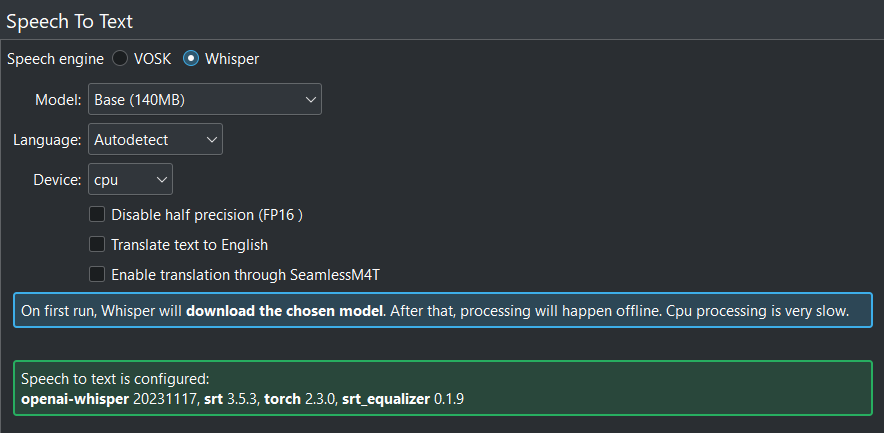
When all is configured correctly you get this screen: All green!¶
Path where Whisper is installed:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
The Whisper speech models are stored here:
- Linux:
~/.local/share/kdenlive/opencvmodels- Windows:
%AppData%\kdenlive\opencvmodels
To download and start subtitle translation follow these steps.
You can check for updates by clicking on Check configuration
If you have installed Whisper in an earlier Kdenlive version, and now you have chosen the venv folder for Python, you can delete the previously installed Whisper libraries by using the following command in a terminal:
$ pip uninstall openai-whisper
Bemerkung
If you get consistent messages during speech recognition about missing model files, check where clicking on the link next to Models folder takes you. If it is ~/.cache where there is a folder Whisper containing all the models you downloaded, simply copy this folder to where the error message says they are missing (most likely: ~/.var/app/org.kde.kdenlive/cache)