Riconoscimento vocale¶
Nuovo nella versione 21.04.0.
Avvertimento
Il riconoscimento vocale non funziona nella versione 21.04.2 a causa di alcuni problemi con l”API Vosk. Usa la versione 21.04.1, oppure la 21.04.3 o le successive.
Installare Python¶
Python 3 needs to be installed on your computer (details see below for Linux and Windows). Once Python is installed, follow these steps to put Python into a virtual environment (afterwards Python is copied to the venv folder)
De-install Python
To remove the installed venv package got to and Delete venv.
It will completely remove the venv folder with all installed packages. Note that this does not remove the downloaded models (vosk/whisper) that can still take quite some HD space
Linux¶
Python è installato per impostazione predefinita nella maggior parte delle distribuzioni Linux. Puoi verificare se è anche il tuo caso eseguendo python3 -V in un terminale. Se non lo è, cerca in Internet: ci sono un sacco di istruzioni a riguardo.
Windows¶
Scarica python da https://www.python.org/downloads/ per l’installazione nel computer.
Motori vocali¶
To install the speech engines go to .
VOSK¶
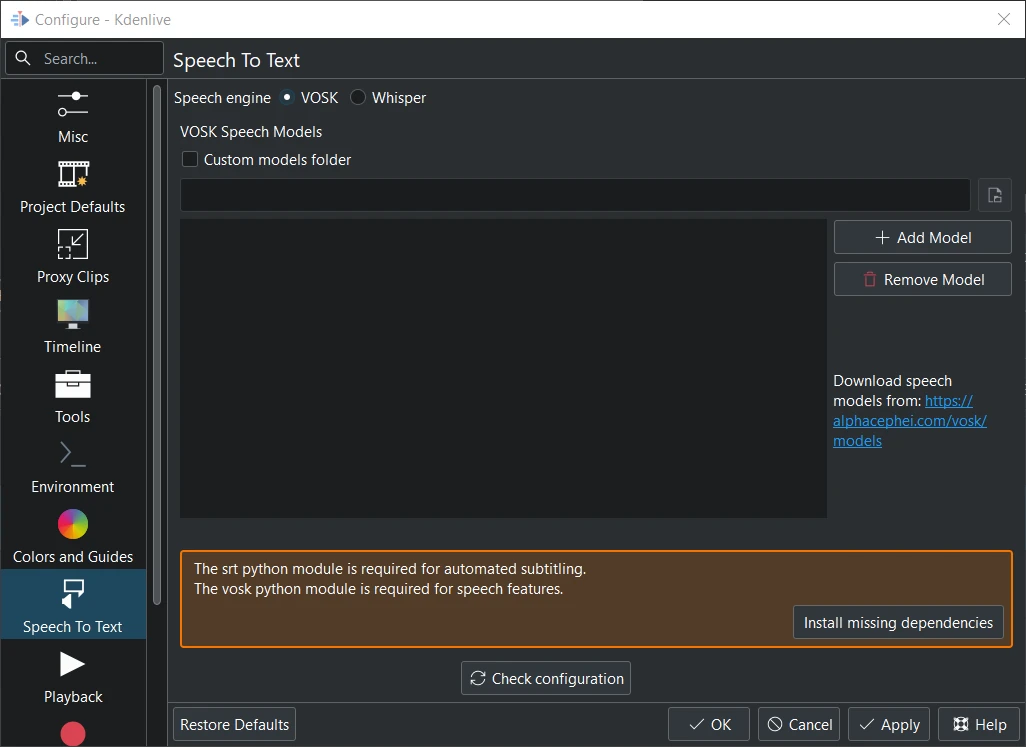
Vosk is not installed¶
When you switch to VOSK for the first time you have to install the missing dependencies first.
Path where VOSK is installed:
Linux:
~/.local/share/kdenlive/venv/LibWindows:
%LocalAppData%\kdenlive\venv\Lib
If you have installed VOSK in an earlier Kdenlive version already and now you have chosen the venv folder for Python, you can delete the past installed VOSK libraries by using following command in a console: pip uninstall vosk srt
Installare una lingua¶
Vai in , e seleziona il motore vocale VOSK
Fai clic sul collegamento per ottenere un modello di lingua.
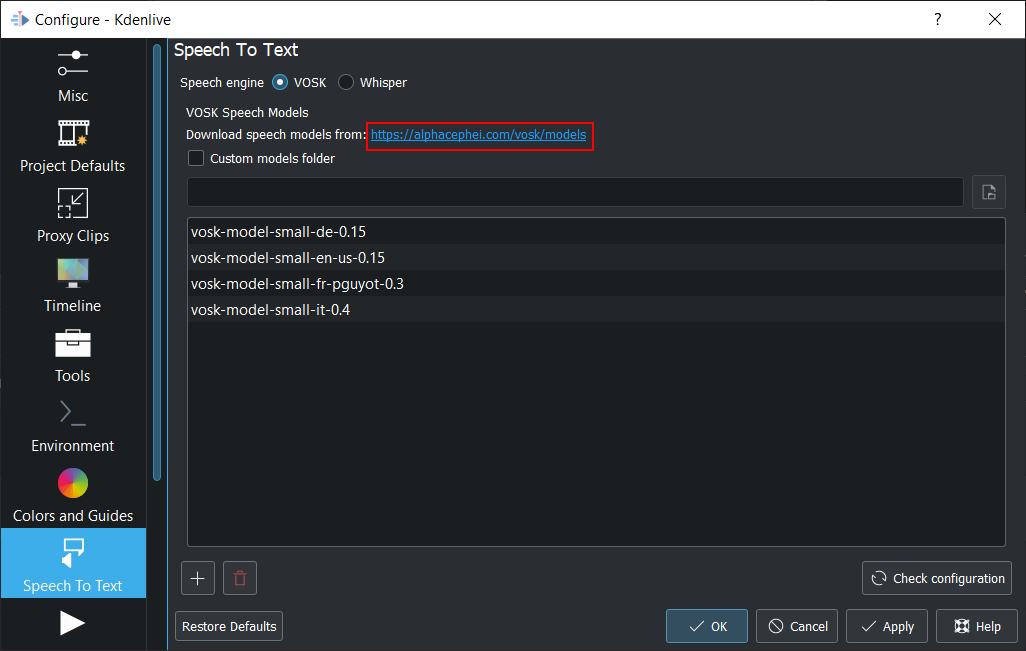
Trascina la lingua che vuoi dalla pagina di scaricamento dei modelli vosk nella finestra dei modelli: verrà scaricato ed estratto per te.
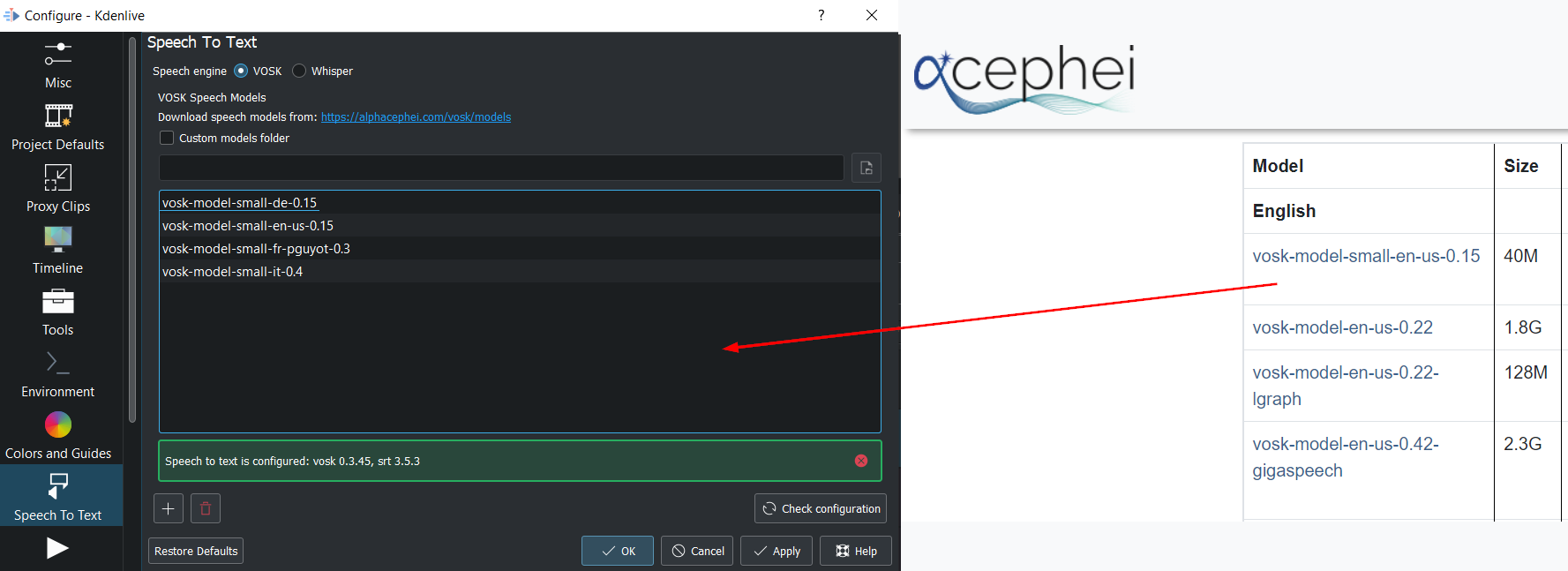
Se hai problemi, o se vuoi controllare la disponibilità di aggiornamenti, premi il pulsante Controlla la configurazione.
The VOSK speech models are stored here:
Linux: ~/.local/share/kdenlive/speechmodels
Windows: %AppData%\kdenlive\speechmodels
Whisper¶
Nuovo nella versione 23.04.
OpenAI-Whisper è un modello di riconoscimento vocale per uso generale. È stato addestrato mediante un vasto insieme di dati di vari audio, ed è in grado di eseguire la traduzione vocale e l’identificazione della lingua.
Whisper è più lento di VOSK nella CPU, ma è più accurato: crea delle frasi coi segni di punteggiatura anche in modalità Base.
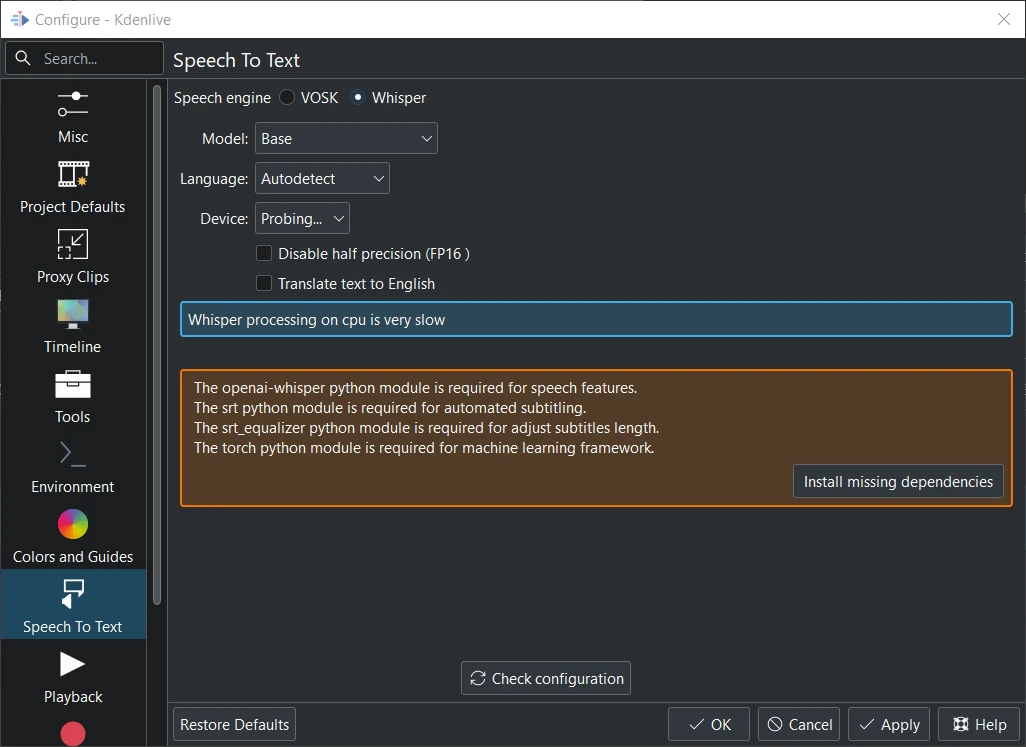
Whisper is not installed¶
Quando passi per la prima volta a Whisper, devi prima installare le dipendenze mancanti (circa 2 GB da scaricare).
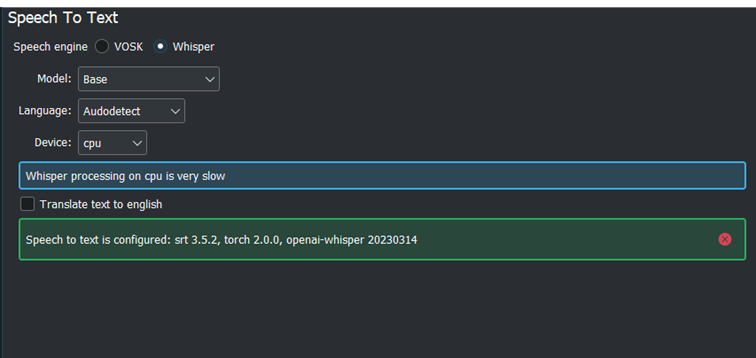
Quando tutto sarà correttamente configurato avrai questa schermata.
Path where Whisper is installed:
Linux:
~/.local/share/kdenlive/venv/LibWindows:
%LocalAppData%\kdenlive\venv\Lib
The Whisper speech models are stored here:
Linux: ~/.local/share/kdenlive/opencvmodels
Windows: %AppData%\kdenlive\opencvmodels
Modello seleziona il modello. Maggiori dettagli in Whisper source code page (predefinito: Base)
Lingua seleziona la lingua se Rileva automaticamente non è accurato (predefinito: Rileva automaticamente)
Dispositivo per mantenere la compatibilità è disponibile solo CPU.
Traduci il testo in inglese durante il riconoscimento traduce in inglese il testo che non è in inglese.
Puoi controllare la disponibilità di aggiornamenti premendo il pulsante Controlla la configurazione
If you have installed Whisper in an earlier Kdenlive version already and now you have chosen the venv folder for Python, you can delete the past installed Whisper libraries by using following command in a console: pip uninstall openai-whisper
Riconoscimento vocale¶
Selezionare il motore vocale¶
Nuovo nella versione 23.04.
Abilita la voce di menu .
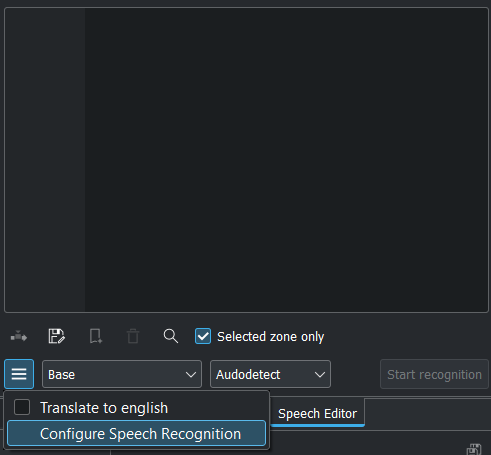
Fai clic sul menu Hamburger  e seleziona Configura il riconoscimento vocale. Questo ti porta a Configura il riconoscimento vocale, seleziona il motore, poi fai clic su OK.
e seleziona Configura il riconoscimento vocale. Questo ti porta a Configura il riconoscimento vocale, seleziona il motore, poi fai clic su OK.
Traduci in inglese è disponibile solamente col motore vocale Whisper. Durante il riconoscimento traduce in inglese il testo che non lo è già.
Creazione di sottotitoli mediante riconoscimento vocale¶
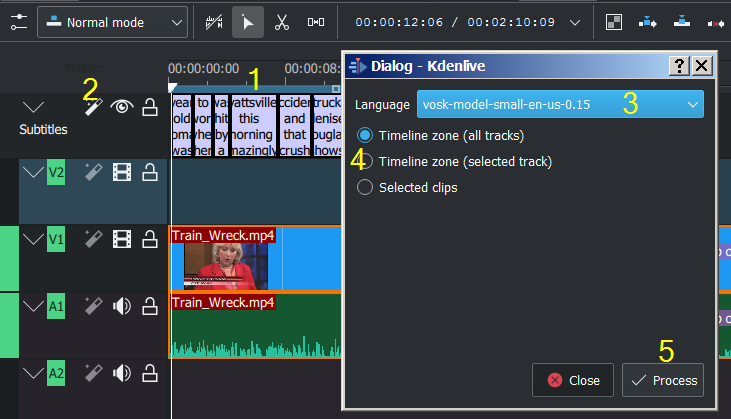
Mostrato con il motore VOSK¶
Segna la zona della linea temporale che vuoi riconoscere (regola la linea blu)
Fai clic sull’icona Riconoscimento vocale
Scegli la lingua
Scegli come dovrebbe essere applicata la zona selezionata
Premi il pulsante Elabora
I sottotitoli vengono creati e inseriti automaticamente.
Nota
Per adesso solo la zona della linea temporale è stata implementata per i sottotitoli automatici.
Nota sul punto 4: il predefinito è analizzare solamente la Zona dalla linea temporale (tutte le tracce), cioè la barra blu nel righello della linea temporale. Imposta la zona della linea temporale a quello che vuoi analizzare (usa I e O per impostare i punti di attacco e di stacco). L’opzione Clip selezionate analizza solamente le clip selezionate.
Creare clip mediante il riconoscimento vocale¶
È utile per interviste e per altri filmati relativi al parlato. Abilita la voce di menu .
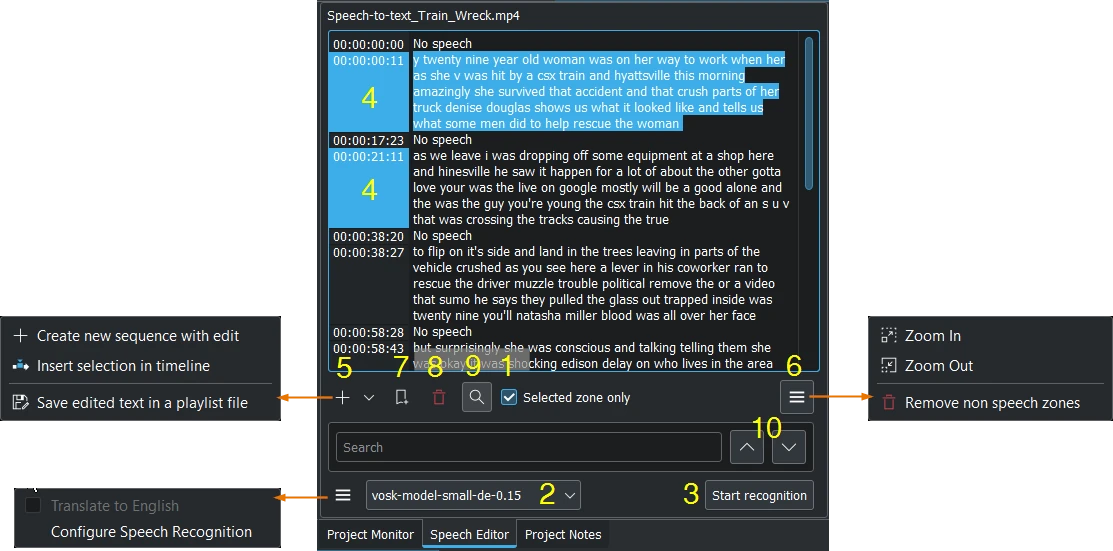
Shown with the VOSK engine and search enabled¶
Select a clip in the Project Bin.
Se necessario imposta i punti di attacco e di stacco nel controllo della clip, e abilita il rettangolo di selezione Seleziona solo la zona: in questo modo verrà riconosciuto il testo all’interno della zona.
Choose the correct language when the VOSK engine is selected. Or choose the Whisper engine by click on Configure Speech Recognition (see configure speech to text)
Premi il pulsante Inizia il riconoscimento.
Select the text you want. Holding CTRL or Shift to select several texts.
Choose: Create new sequence with edit creates a new sequence with each timecode-text as a single clip, or Insert selection in timeline at playhead position, or to Save edited text in a playlist file which appears in the project bin.
Zoom in or Zoom out of the text. Remove non speech zones deletes all «No speech» entries at once.
Aggiungere un segnalibro: in questo modo potrai saltare a questi segnalibri nella linea temporale con la scorciatoia Alt + freccia, oppure modificare il segnalibro con un doppio clic.
Delete the selected text.
Qui puoi cercare nel testo.
E navigare su e giù nel testo.
Rilevamento del silenzio¶
Funziona solo col motore VOSK.
Apri una clip nel monitor della clip, e anche la finestra dell’editor () .
Seleziona la lingua, oppure vedi Motori vocali e scarica il suo modello.
Quindi fai clic sul pulsante Inizia il riconoscimento.
Once this is done, choose under point 6 from above to Remove non speech zones at once. Or click on the time-code where «No speech» is indicated (hold Ctrl to select several items at once) and just hit the Delete key.
Repeat the operation for all the parts you want to remove, including where someone says what you do not want to include in your final edit.
Once finished, make sure Selected zone only is disabled, click on the Save edited text in a playlist file button (above under point 5) and after few seconds a new playlist is added in the Project Bin without silence and without the text you do not want.