Govor v besedilo
Opozorilo
Govor v besedilo ne deluje z različico 21.04.2 zaradi težav z API-jem Vosk. Uporabite različico 21.04.1 ali 21.04.3 in novejše različice.
Preden lahko uporabite govor v besedilo, mora biti pravilno nastavljen in namestiti morate govorne modele. Glejte poglavje Prilagoditev govora v besedilo.
Nasvet
Medtem ko lahko prilagodite in nastavite oba, VOSK in Whisper, bo za razpoznavanje govora uporabljen mehanizem, ki je izbran v prilagoditvenem razdelku Govor v besedilo. Med montažo lahko seveda preklapljate sem ter tja in uporabljate različne mehanizme za različne namene. Pripomoček urejevalnika govora ima vnos v meniju za hiter dostop do prilagoditvenega razdelka, ki se izogne poti Govor v besedilo.
Razpoznavanje govora
Obstajata dva primera uporabe prepoznavanje govora:
Samodejno ustvarjanje podnaslovov
Ustvarjanje transkripcij in možnost dodajanja posnetkov na časovnico na podlagi prepisa oz. transkripcije.
Ustvarjanje podnaslovov s prepoznavo govora VOSK
Če še ni ustvarjena, dodajte stezo podnaslovov s klikom ikone  Orodje Uredi podnaslov v orodni vrstici časovnice (6).
Orodje Uredi podnaslov v orodni vrstici časovnice (6).
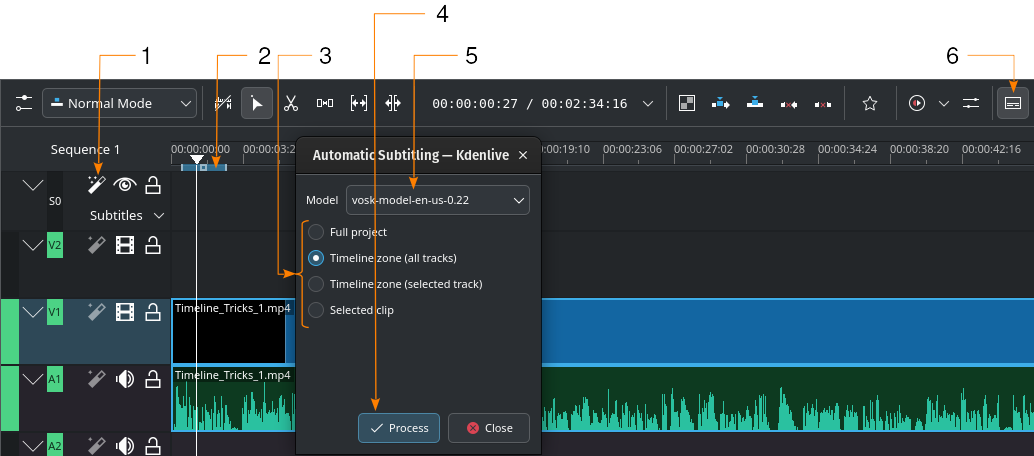
Samodejno tvorjenje podnaslovov z uporabo mehanizma VOSK
- 1:
 Prepoznavanje govora. Kliknite tukaj, da odprete pogovorno okno Samodejno podnaslavljanje.
Prepoznavanje govora. Kliknite tukaj, da odprete pogovorno okno Samodejno podnaslavljanje.- 2:
Območje časovnice. Več podrobnosti o območjih časovnice lahko najdete v poglavju Ravnilo časovnice.
- 3:
Izberite, kateri del časovnice bo uporabljen za prepoznavo govora (4).
- 4:
Obdelaj. Kliknite za začetek prepoznavanja
- 5:
Model. Izberite model za jezik podnaslovov. Več modelov lahko namestite v razdelku Prilagoditev Govor v besedilo.
- 6:
- Orodje za urejanje podnaslovov. Kliknite, da odprete ali zaprete stezo podnaslovov.
Ustvarjanje podnaslovov s prepoznavo govora VOSK
(številke v oklepajih kažejo na element vmesnika na zgornjem zajemu zaslona):
- Prepoznavanje govora (1). Kliknite tukaj, da odprete pogovorno okno Samodejno podnaslavljanje.
Po potrebi določite območje časovnice (2), za katero želite uporabiti razpoznavanje govora. Več podrobnosti o območjih časovnice lahko najdete v poglavju Ravnilo časovnice.
Model`(**5**). Izberite model za jezik podnaslovov. Več modelov lahko namestite v razdelku Prilagoditev :doc:`Govor v besedilo </getting_started/configure_kdenlive/configuration_plugins>.
Izberite, kateri del časovnice bo uporabljen za razpoznavo govora (4).
Obdelaj (4). Kliknite za začetek izdelave podnaslovov.
Podnaslov se samodejno ustvari in vstavi.
Opomba k 4: Privzeto se analizira samo območje časovnice (vse steze) (2 na zgornji zaslonski sliki). Nastavite območje v časovnici na tisto, kar želite analizirati (uporabite tipki I in O za nastavitev vhodnih in izhodnih točk). Možnost Izbrani posnetki analizira samo izbrani posnetek.
Ustvarjanje podnaslovov s prepoznavo govora WHISPER
Če še ni ustvarjena, dodajte stezo podnaslovov s klikom ikone Orodje Uredi podnaslov v orodni vrstici Časovnica (11).
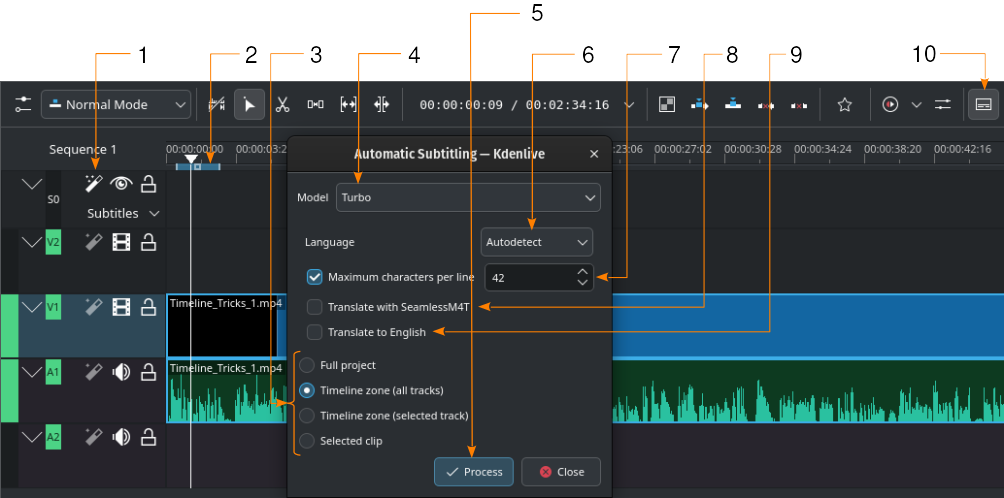
Samodejno tvorjenje podnaslovov z uporabo mehanizma Whisper
- 1:
- Prepoznavanje govora. Kliknite tukaj, da odprete pogovorno okno Samodejno podnaslavljanje.
- 2:
Območje časovnice. Več podrobnosti o območjih časovnice lahko najdete v poglavju Ravnilo časovnice.
- 3:
Izberite, kateri del časovnice bo uporabljen za prepoznavo govora (4).
- 4:
Model. Izberite model za jezik podnaslovov. Več modelov lahko namestite v razdelku Prilagoditev Govor v besedilo.
- 5:
Obdelaj. Kliknite za začetek prepoznavanja
- 6:
Jezik. Privzeta vrednost je Samodejno zaznaj. Če ne zaznna pravega jezika, lahko jezik nastavite ročno.
- 7:
Največ znakov na vrstico. Določite, koliko znakov na vrstico je dovoljenih pred vstavljanjem preloma vrstice.
- 8:
Prevedi s SeamlessM4T. Če potrdite to, dodate še dve izbirni polji: eno za Vhodni jezik ` in eno za :guilabel:`Izhodni jezik. To zahteva, da je prevod s SeamlessM4T omogočen v nastavitvah (). Glejte poglavje o Govor v besedilo.
- 9:
Prevedi v angleščino. To je na voljo le z govornim ustrojem Whisper. Prevaja neangleško besedilo v angleščino med razpoznavanjem.
- 10:
- Orodje za urejanje podnaslovov. Kliknite, da odprete ali zaprete stezo podnaslovov.
Ustvarjanje podnaslovov s prepoznavo govora VOSK
(številke v oklepajih kažejo na element vmesnika na zgornjem zajemu zaslona):
- Prepoznavanje govora (1). Kliknite tukaj, da odprete pogovorno okno Samodejno podnaslavljanje.
Po potrebi določite območje časovnice (2), za katero želite uporabiti razpoznavanje govora. Več podrobnosti o območjih časovnice lahko najdete v poglavju Ravnilo časovnice.
Model`(**5**). Izberite model za jezik podnaslovov. Več modelov lahko namestite v razdelku Prilagoditev :doc:`Govor v besedilo </getting_started/configure_kdenlive/configuration_plugins>.
Izberite, kateri del časovnice bo uporabljen za razpoznavo govora (4).
Obdelaj (4). Kliknite za začetek izdelave podnaslovov.
Podnaslov se samodejno ustvari in vstavi.
Opomba k 4: Privzeto se analizira samo območje časovnice (vse steze) (2 na zgornji zaslonski sliki). Nastavite območje v časovnici na tisto, kar želite analizirati (uporabite tipki I in O za nastavitev vhodnih in izhodnih točk). Možnost Izbrani posnetki analizira samo izbrani posnetek.
Prevedi s SeamlessM4T
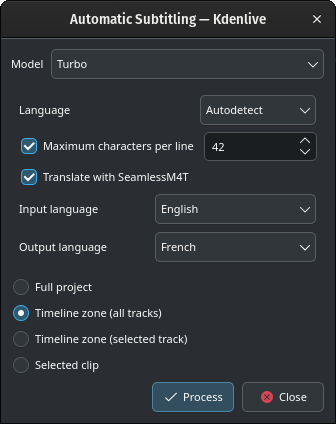
Prevajanje s SeamlessM4T
Izberite Vhodni jezik in Izhodni jezik ter kliknite Obdelaj.
To bo najprej obdelalo zvok z Whisperjem, nato pa zagnalo prevod s SeamlessM4T. Prevajanje lahko zasede 100 % RAM-a, 100 % CPE in 100 % dostopov do diskov.
Pozor
Če model 9 GB še ni bil prenesen, bo prenesen zdaj. Pri hitrosti prenosa 100 MB/s bo to trajalo približno 12 minut!
Med prenosom se bo Kdenlive odzival kot običajno. Ne kliknite Zapri, sicer se prenos ustavi.
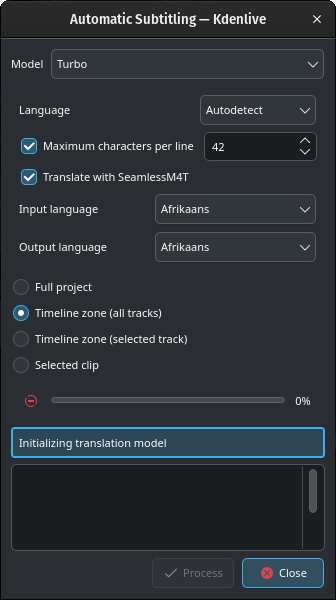
Ne skrbite, če se v spodnjem polju prikaže sporočilo Inicializacija prevajalnega modela, medtem ko poteka prenos.
Glede na vašo internetno povezavo in pasovno širino lahko prenos modela traja kar nekaj časa (približno 12 minut pri hitrosti prenosa 100 MB/s).
Ko prenesete prevajalski model, se bo prevajanje začelo.
Ustvarjanje posnetkov s prepoznavanjem govora
To je uporabno za intervjuje in druge posnetke, povezane z govorjeno besedo. Vstopite v gradnik Urejevalnik govora. Če ni omogočen, to storite prek .
Opomba
Uporaba razpoznavanja govora za ustvarjanje prepisov in ustvarjanje posnetkov iz le-teh je mogoča le s posnetki v projektni posodi.
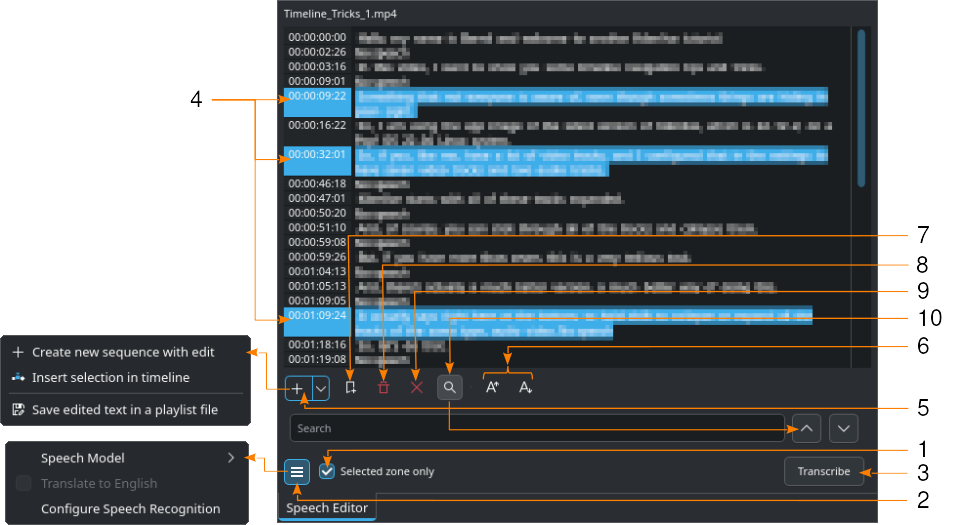
Prikazano s pogonom VOSK in omogočenim iskanjem (10)
Izberite posnetek v projektni posodi.
- 1:
Po potrebi nastavite vhodno/izhodno točko v ogledu posnetka in potrdite polje Samo izbrano območje. To bo transkribiralo samo besedilo znotraj območja.
- 2:
Kliknite
 meni hamburgerja in izberite model za pravi jezik, ko je za prepoznavo govora nastavljen mehanizem VOSK. Če je izbran Whisper, lahko po potrebi izberete Prevedi v angleščino. Mehanizem za prepoznavanje govora izberete pod . Kliknite Prilagodi prepoznavanje govora, da odprete razdelek za prilagajanje Govora v besedilo. Za več podrobnosti o prilagoditvah glejte poglavje Prilagoditev govora v besedilo.
meni hamburgerja in izberite model za pravi jezik, ko je za prepoznavo govora nastavljen mehanizem VOSK. Če je izbran Whisper, lahko po potrebi izberete Prevedi v angleščino. Mehanizem za prepoznavanje govora izberete pod . Kliknite Prilagodi prepoznavanje govora, da odprete razdelek za prilagajanje Govora v besedilo. Za več podrobnosti o prilagoditvah glejte poglavje Prilagoditev govora v besedilo.- 3:
Pritisnite gumb Transkribiraj.
- 4:
Izberite želeno besedilo. Držite pritisnjeno krmilko ali dvigalko, da izberete več besedil.
- 5:
Izberite: Ustvari novo zaporedje z urejanjem ustvari novo zaporedje z vsakim besedilom časovne kode kot enim posnetkom. Vstavi izbor na časovnico ustvari posnetke za vsako izbrano dvojico časovna koda - besedilo na položaju predvajalne glave. Shrani urejeno besedilo v datoteko seznama predvajanja, ustvari vir v projektni posodi s celotnim izpisanim besedilom.
- 6:
 Povečaj velikost pisave in
Povečaj velikost pisave in  Zmanjšaj velikost pisave povečata oz. zmanjšata velikost pisave.
Zmanjšaj velikost pisave povečata oz. zmanjšata velikost pisave.- 7:
 Dodaj označevalnik doda označevalnik za časovno kodo izbranega besedila. Več podrobnosti o Označevalnikih časovnice in Označevalnikih je na voljo v poglavju Označevalniki časovnice.
Dodaj označevalnik doda označevalnik za časovno kodo izbranega besedila. Več podrobnosti o Označevalnikih časovnice in Označevalnikih je na voljo v poglavju Označevalniki časovnice.- 8:
 Izbriši izbor izbriše izbrano besedilo.
Izbriši izbor izbriše izbrano besedilo.- 9:
Odstrani območja brez govora izbriše vse vnose »Brez govora« hkrati.
- 10:
 Iskanje v besedilu preklopi iskalno polje. Vnesite besedilo, ki ga želite poiskati v transkribiranem besedilu. Iskanje ne razlikuje med velikimi in malimi črkami in najde vse pojavitve niza, tudi znotraj besed.
Iskanje v besedilu preklopi iskalno polje. Vnesite besedilo, ki ga želite poiskati v transkribiranem besedilu. Iskanje ne razlikuje med velikimi in malimi črkami in najde vse pojavitve niza, tudi znotraj besed.  in
in  pomakneta do naslednjega pojava iskanega izraza. Če iskalno polje postane rdečkasto, ste dosegli zadnji pojav iskalnega izraza v besedilu.
pomakneta do naslednjega pojava iskanega izraza. Če iskalno polje postane rdečkasto, ste dosegli zadnji pojav iskalnega izraza v besedilu.
Zaznavanje tišine
Opomba
To deluje samo s pogonom VOSK.
Odprite posnetek v projektni posodi in odprite okno urejevalnika govora () .
Kliknite meni hamburgerja in izberite model za svoj jezik. Če pravi model ni naveden, kliknite Prilagodi prepoznavanje govora. Za podrobnosti o tem, kako dodati modele za pogon VOSK, glejte poglavje Vstavki.
Nato kliknite gumb Začni razpoznavanje.
Ko to storite, izberite pod zgornjo točko 6 do Odstrani območja brez govora hkrati. Ali pa kliknite časovno kodo, kjer je označeno »Brez govora« (držite pritisnjeno krmilko, da izberete več elementov hkrati) in samo pritisnite Brisalko.
Ponovite operacijo za vse dele, ki jih želite odstraniti, vključno s tem, kje nekdo nekaj pove, česar ne želite vključiti v končno montažo.
Ko končate, se prepričajte, da je Samo izbrano območje onemogočeno, kliknite gumb Shrani urejeno besedilo v datoteko seznama predvajanja (zgoraj pod točko 5) in po nekaj sekundah se v projektno posodo doda nov seznam predvajanja brez tišine in brez besedila, ki ga ne želite.