Перетворення звуку на текст
Попередження
Перетворення мовлення у текст не працює у версії 21.04.2 через проблеми із програмним інтерфейсом Vosk. Скористайтеся версією 21.04.1 або 21.04.3 чи новішими версіями.
Перш ніж використовувати функціональну можливість «Перетворення звуку на текст», її потрібно правильно налаштувати та встановити моделі мовлення. Будь ласка, зверніться до розділу Налаштовування перетворення звуку на текст.
Підказка
Хоча ви можете налаштувати обидва рушії, VOSK і Whisper, для розпізнавання мовлення, рушій, який буде вибрано у розділі налаштувань Перетворення звуку на текст, буде використано для розпізнавання мовлення наступного разу під час використання цієї функціональної можливості. Звичайно, ви можете перемикатися між рушіями під час редагування та використовувати різні рушії для різних цілей. У віджеті «Редактор озвучення» є пункт меню для швидкого доступу до розділу налаштувань, оминаючи потребу у послідовному виборі Перетворення мовлення на текст.
Розпізнавання мовлення
Розпізнаванням мовлення можна скористатися у двох випадках:
Автоматичне створення субтитрів
Створення транскрибування і можливість додавання кліпів на монтажний стіл на основі транскрибування
Створення субтитрів за допомогою розпізнавання мовлення з VOSK
Якщо доріжку не створено, додайте доріжку субтитрів натисканням піктограми  Інструмент редагування субтитрів на панелі інструментів монтажного столу (6).
Інструмент редагування субтитрів на панелі інструментів монтажного столу (6).
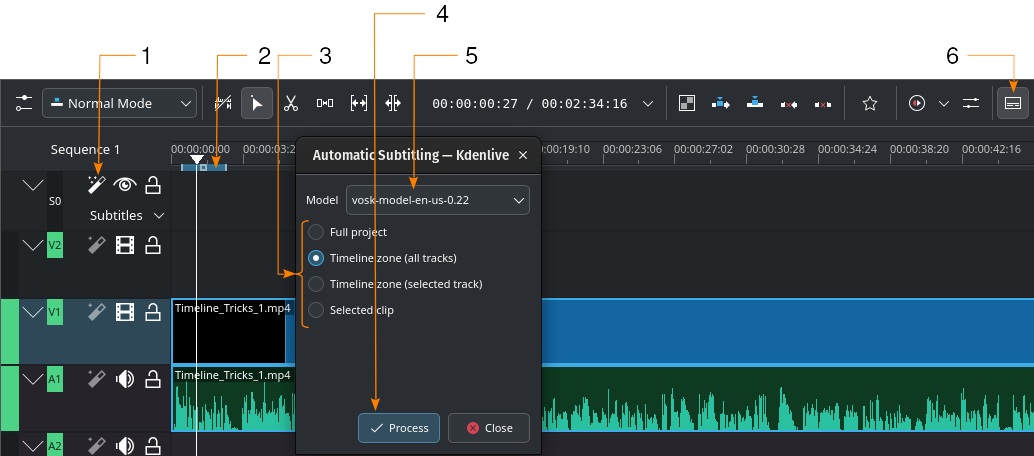
Автоматичне створення субтитрів за допомогою рушія VOSK
- 1:
 Розпізнавання мовлення. Натисніть, щоб відкрити діалогове вікно Автоматичне субтитрування.
Розпізнавання мовлення. Натисніть, щоб відкрити діалогове вікно Автоматичне субтитрування.- 2:
Зона монтажного столу. Докладніший опис зон монтажного столу наведено у розділі Лінійка монтажного столу.
- 3:
Виберіть частину монтажного столу, до якої має бути застосовано розпізнавання мовлення
- 4:
Обробка. Натисніть, щоб розпочати розпізнавання
- 5:
Модель. Виберіть модель для мови субтитрів. Додаткові моделі можна встановити у розділі налаштувань Перетворення мовлення на текст.
- 6:
- Інструмент редагування субтитрів. Натисніть, щоб відкрити або закрити доріжку субтитрів.
Кроки створення субтитрів за допомогою розпізнавання мовлення з VOSK
(число у дужках вказує на елемент графічного інтерфейсу на наведеному вище знімку вікна):
- Розпізнавання мовлення (1). Натисніть, щоб відкрити діалогове вікно Автоматичне субтитрування.
Якщо потрібно, визначте зону монтажного столу (2), для якої слід виконати розпізнавання мовлення. Докладніший опис зон монтажного столу наведено у розділі Лінійка монтажного столу.
Модель (5). Виберіть модель для мови субтитрів. Додаткові моделі можна встановити у розділі налаштувань Перетворення мовлення на текст.
Виберіть частину монтажного столу, до якої має бути застосовано розпізнавання мовлення (3)
Обробка (4). Натисніть, щоб розпочати створення субтитрів.
Субтитри буде створено і вставлено автоматично.
Зауваження щодо кроку 4: типова поведінка полягає в аналізі лише зони монтажного столу (усі доріжки) (2 на наведеному вище знімку). Встановіть на монтажному столі зону, аналіз якої слід виконати (скористайтеся клавішами I і O для встановлення вхідної і вихідної позицій). Якщо буде позначено пункт Позначені кліпи, програма виконає аналіз лише позначених кліпів.
Створення субтитрів за допомогою рушія розпізнавання мовлення WHISPER
Якщо доріжку не створено, додайте доріжку субтитрів натисканням піктограми Інструмент редагування субтитрів на панелі інструментів монтажного столу (11).
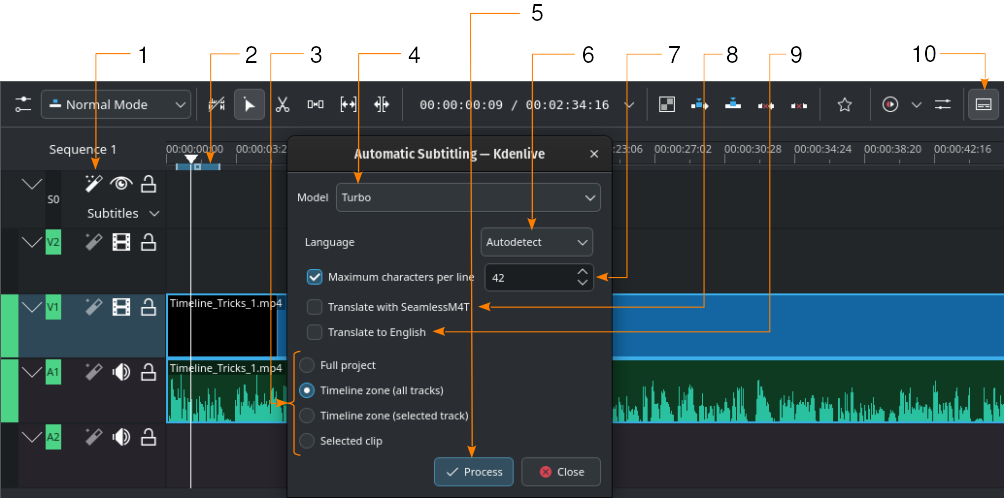
Автоматичне створення субтитрів за допомогою рушія Whisper
- 1:
- Розпізнавання мовлення. Натисніть, щоб відкрити діалогове вікно Автоматичне субтитрування.
- 2:
Зона монтажного столу. Докладніший опис зон монтажного столу наведено у розділі Лінійка монтажного столу.
- 3:
Виберіть частину монтажного столу, до якої має бути застосовано розпізнавання мовлення
- 4:
Модель. Виберіть модель для мови субтитрів. Додаткові моделі можна встановити у розділі налаштувань Перетворення мовлення на текст.
- 5:
Обробка. Натисніть, щоб розпочати розпізнавання
- 6:
Мова. Типовим варіантом є Автовиявлення. Змініть мову на відповідну, якщо виявлення не спрацювало належним чином.
- 7:
Максимальна кількість символів на рядок. Визначає кількість символів у рядку, перш ніж буде вставлено символ розриву рядка.
- 8:
Перекласти за допомогою SeamlessM4T. Позначення цього пункту надає доступ до двох додаткових полів: одного для Початкова мова і одного для Мова перекладу. Це потребує вмикання перекладу за допомогою SeamlessM4T у параметрах програми (). Будь ласка, зверніться до розділу щодо Перетворення мовлення на текст, щоб дізнатися більше.
- 9:
Пункт Перекласти текст англійською. Позначте, якщо слід використати Whisper для перекладу англійською.
- 10:
- Інструмент редагування субтитрів. Натисніть, щоб відкрити або закрити доріжку субтитрів.
Кроки створення субтитрів за допомогою розпізнавання мовлення з VOSK
(число у дужках вказує на елемент графічного інтерфейсу на наведеному вище знімку вікна):
- Розпізнавання мовлення (1). Натисніть, щоб відкрити діалогове вікно Автоматичне субтитрування.
Якщо потрібно, визначте зону монтажного столу (2), для якої слід виконати розпізнавання мовлення. Докладніший опис зон монтажного столу наведено у розділі Лінійка монтажного столу.
Модель (5). Виберіть модель для мови субтитрів. Додаткові моделі можна встановити у розділі налаштувань Перетворення мовлення на текст.
Виберіть частину монтажного столу, до якої має бути застосовано розпізнавання мовлення (3)
Обробка (4). Натисніть, щоб розпочати створення субтитрів.
Субтитри буде створено і вставлено автоматично.
Зауваження щодо кроку 4: типова поведінка полягає в аналізі лише зони монтажного столу (усі доріжки) (2 на наведеному вище знімку). Встановіть на монтажному столі зону, аналіз якої слід виконати (скористайтеся клавішами I і O для встановлення вхідної і вихідної позицій). Якщо буде позначено пункт Позначені кліпи, програма виконає аналіз лише позначених кліпів.
Перекласти за допомогою SeamlessM4T
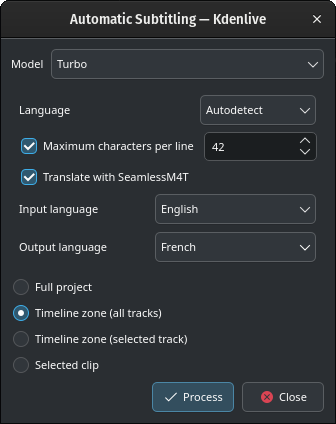
Переклад за допомогою SeamlessM4T
Виберіть Початкову мову і Мову перекладу і натисніть кнопку Обробка.
Спочатку буде оброблено звукові дані за допомогою Whisper, потім буде запущено переклад за допомогою SeamlessM4T. Для перекладу може знадобитися 100% оперативної пам’яті, 100% потужностей процесора та 100% можливостей доступу до диска.
Увага
Якщо модель у 9 ГБ ще не було отримано, її буде отримано. Зі швидкістю 100 МБ/с отримання даних буде тривати 12 хвилин!
Під час отримання даних Kdenlive працюватиме у звичному режимі. Не натискайте кнопку Закрити, якщо не хочете перервати отримання даних.
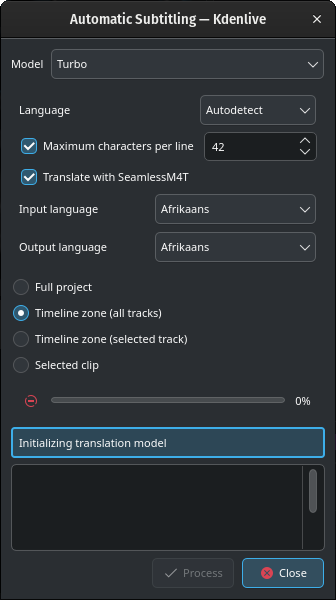
Не переймайтеся, якщо побачите таке повідомлення на панелі під пунктом Ініціалізація моделі перекладу, доки триває отримання даних.
Залежно від вашого інтернет-з’єднання та ширини каналу зв’язку, отримання моделі може бути досить тривалим (приблизно 12 хвилин при швидкості отримання даних у 100 МБ/с).
Щойно отримання моделі перекладу буде завершено, програма розпочне переклад.
Створення кліпів з використанням розпізнаванням мовлення
Ця можливість корисна для інтерв’ю та іншого пов’язаного із голосовими даними матеріалу. Відкрийте віджет редактора озвучення. Якщо його ще не увімкнено, скористайтеся пунктом меню .
Примітка
Скористатися розпізнаванням мовлення для створення транскрибування та кліпів на його основі, можливе лише для кліпів у Контейнері проєкту.
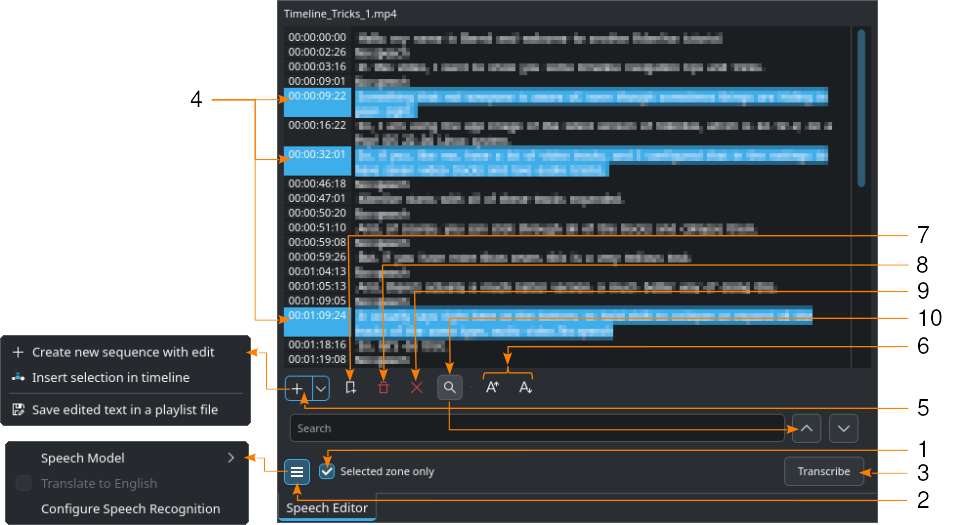
Показано з рушієм VOSK і увімкненим пошуком (10)
Виберіть кліп на панелі контейнера проєкту.
- 1:
Якщо потрібно, встановіть точки входу і виходу на моніторі кліпу і позначте пункт Лише позначена ділянка. У результаті буде розпізнано текст лише з вказаної ділянки.
- 2:
Натисніть кнопку
 Меню-гамбургера і виберіть правильну модель для мови, якщо на розпізнавання мовлення налаштовано рушій VOSK. Якщо вибрано рушій Whisper, ви можете позначити пункт Перекласти англійською мовою, якщо це потрібно. Вибрати рушій розпізнавання мовлення можна за допомогою пункту . Натисніть Налаштувати розпізнавання мовлення, щоб відкрити розділ налаштувань для перетворення мовлення на текст. Щоб дізнатися більше про налаштування, зверніться до розділу Налаштування перетворення мовлення на текст.
Меню-гамбургера і виберіть правильну модель для мови, якщо на розпізнавання мовлення налаштовано рушій VOSK. Якщо вибрано рушій Whisper, ви можете позначити пункт Перекласти англійською мовою, якщо це потрібно. Вибрати рушій розпізнавання мовлення можна за допомогою пункту . Натисніть Налаштувати розпізнавання мовлення, щоб відкрити розділ налаштувань для перетворення мовлення на текст. Щоб дізнатися більше про налаштування, зверніться до розділу Налаштування перетворення мовлення на текст.- 3:
Натисніть кнопку Транскрибувати.
- 4:
Виберіть бажаний фрагмент тексту. Шляхом утримання натиснутими клавіш Ctrl або Shift можна вибрати одразу декілька фрагментів тексту.
- 5:
Створити послідовність із редагуванням — створити послідовність із прив’язками часових позначок до тексту як окремий кліп. Вставити позначене на монтажний стіл створює кліпи для кожної вибраної часової позначки і тексту, починаючи з позиції відтворення. Зберегти редагований текст до файла списку відтворення створює пункт на панель контейнера проєкту для усього транскрибованого тексту.
- 6:
 Збільшити розмір шрифту і
Збільшити розмір шрифту і  Зменшити розмір шрифту — збільшити або зменшити розмір шрифту.
Зменшити розмір шрифту — збільшити або зменшити розмір шрифту.- 7:
 Додати позначку — додає позначку для часової позначки позначеного тексту. Докладніше про позначки на монтажному столі і позначки можна дізнатися з розділу Позначки на монтажному столі.
Додати позначку — додає позначку для часової позначки позначеного тексту. Докладніше про позначки на монтажному столі і позначки можна дізнатися з розділу Позначки на монтажному столі.- 8:
 Вилучити позначене вилучає позначений текст.
Вилучити позначене вилучає позначений текст.- 9:
Вилучити усі зони без голосових даних вилучає усі записи без мовлення одразу.
- 10:
 Шукати у тексті перемикає поле пошуку. Введіть фрагмент тексту, який слід знайти у транскрибованому тексті. Пошук не враховує регістр і знаходить усі випадки входження рядка навіть у межах слів. За допомогою кнопок
Шукати у тексті перемикає поле пошуку. Введіть фрагмент тексту, який слід знайти у транскрибованому тексті. Пошук не враховує регістр і знаходить усі випадки входження рядка навіть у межах слів. За допомогою кнопок  і
і  можна перейти до наступного або попереднього входження пошукового терміну. Якщо поле пошуку стає червонуватим, ви досягли останнього входження пошукового терміну в тексті.
можна перейти до наступного або попереднього входження пошукового терміну. Якщо поле пошуку стає червонуватим, ви досягли останнього входження пошукового терміну в тексті.
Виявлення мовчання
Примітка
Працює лише із рушієм VOSK.
Виберіть кліп на панелі Контейнер проєкту і відкрийте вікно редактора озвучення () .
Натисніть кнопку Меню-гамбургера і виберіть модель для вашої мови. Якщо потрібної моделі немає в списку, натисніть Налаштувати розпізнавання мовлення. Щоб дізнатися більше про те, як додати моделі для рушія VOSK, зверніться до розділу про Додатки.
Потім натисніть кнопку Почати розпізнавання.
Щойно цей буде зроблено, виберіть пункт 6 зі знімка вище, щоб Вилучити зони без мовлення, усі одразу. Або натисніть пункт позначки часу, де вказано «Немає озвучення» (утримуйте натиснутою клавішу Ctrl, щоб позначити декілька пунктів одразу), а потім натисніть клавішу Delete.
Повторіть дію для усіх частин, які ви хочете вилучити, включно із частинами, де хтось говорить щось, що не слід включати до остаточного варіанта.
Коли завершите, переконайтеся, що не позначено пункт Лише позначена зона, натисніть кнопку Зберегти редагований текст до файла списку відтворення (над точкою 5), і за декілька секунд на панель контейнера проєкту буде доданого новий список відтворення без проміжків з мовчанням та без небажаного тексту.