Додатки
За допомогою цього розділу можна визначити параметри роботи перетворення звуку на текст та виявлення об’єктів.
Перш ніж можна буде налаштувати та скористатися перетворенням озвучення на текст та виявленням об’єктів, слід встановити Python3. Після встановлення Python3 ви можете скористатися віртуальним середовищем (venv), щоб відокремити Kdenlive від інших частин програмного середовища у вашій системі.
Якщо вами вже встановлено Python3, перейдіть безпосереднього до сторінки налаштувань Перетворення мовлення у текст або Виявлення об’єктів.
Встановлення Python
Встановлення у Linux
У більшості дистрибутивів Linux Python вже типово встановлено. Ви можете перевірити, чи встановлено інтерпретатор у вашій системі, віддавши команду python3 --version у терміналі. Нижче наведено основні кроки для встановлення Python3 в Ubuntu. Якщо ваш дистрибутив не засновано на Ubuntu, зверніться до відповідної документації або знайдіть в інтернеті настанови зі встановлення.
$ sudo apt updates
$ sudo apt install python3
Важливий сторонній пакет Python, який вам може знадобитися, — це pip. У Python 3.4 і новіших версіях типово вже є pip, але не завадить перевірити, віддавши команду command -v pip у терміналі (деякі дистрибутиви використовують pip для Python2 і pip3 для Python 3). Якщо pip немає, ви можете встановити його за допомогою
$ python3 -m ensurepip --upgrade
Якщо виникнуть проблеми, будь ласка, зверніться до pip installation guide.
Примітка
У наступних розділах pip є загальним терміном для всіх версій pip, включаючи pip3. Будь ласка, скористайтеся належною командою pip для вашої операційної системи.
Встановлення у Windows
Отримайте Python з офіційної сторінки Python download.
Виберіть «Додати python.exe до PATH»
Виберіть «Встановити зараз»
Перетворення звуку на текст
За допомогою цього розділу можна налаштувати можливість перетворення озвучення на текст у Kdenlive та керувати різноманітними моделями для двох рушіїв, VOSK і Whisper.
Попередження
Перетворення мовлення у текст не працює у версії 21.04.2 через проблеми із програмним інтерфейсом Vosk. Скористайтеся версією 21.04.1 або 21.04.3 чи новішими версіями.
Рушії озвучення
Доступні два рушії мовлення: VOSK і Whisper. OpenAI-Whisper є модулем розпізнавання мовлення для загального використання Її натреновано на великому наборі даних різних звукових фрагментів, і вона може виконувати переклад та визначення мови.
Whisper є повільнішим за VOSK на процесорі, але є точнішими за VOSK. Whisper створює речення зі знаками пунктуації, навіть у базовому режимі.
Вам слід налаштувати моделі, які буде використано цими рушіями.
Підказка
Якщо ви користуєтеся версією Kdenlive з Flatpak, у вас можуть виникнути проблеми зі встановленням моделей мовлення. Підхід із пісочницею flatpak запобігає запуску pip у kdenlive. Це можна обійти за допомогою команди $ flatpak run --command=/bin/bash org.kde.kdenlive, а потім $ python -m securepip, а потім $ python -m pip install -U openai -whisper torch (поради люб’язно надано Veronica Explains). Складність налаштовування у вашому дистрибутиві може бути різною.
Інший варіант – вибрати Whisper, а потім натиснути Установити багатомовний переклад. У результаті буде отримано і встановлено необхідні залежності та повідомлено Kdenlive про місце, куди ви встановили Python і pip. Після цього ви можете виконати надані тут настанови щодо налаштовування VOSK і Whisper.
VOSK
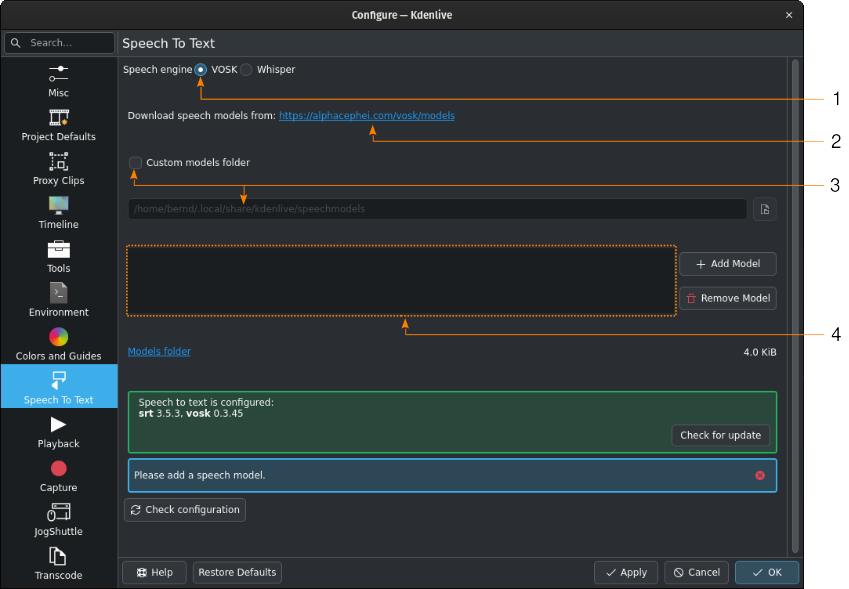
Python працює, але VOSK не може бути використано через нестачу моделей мовлення
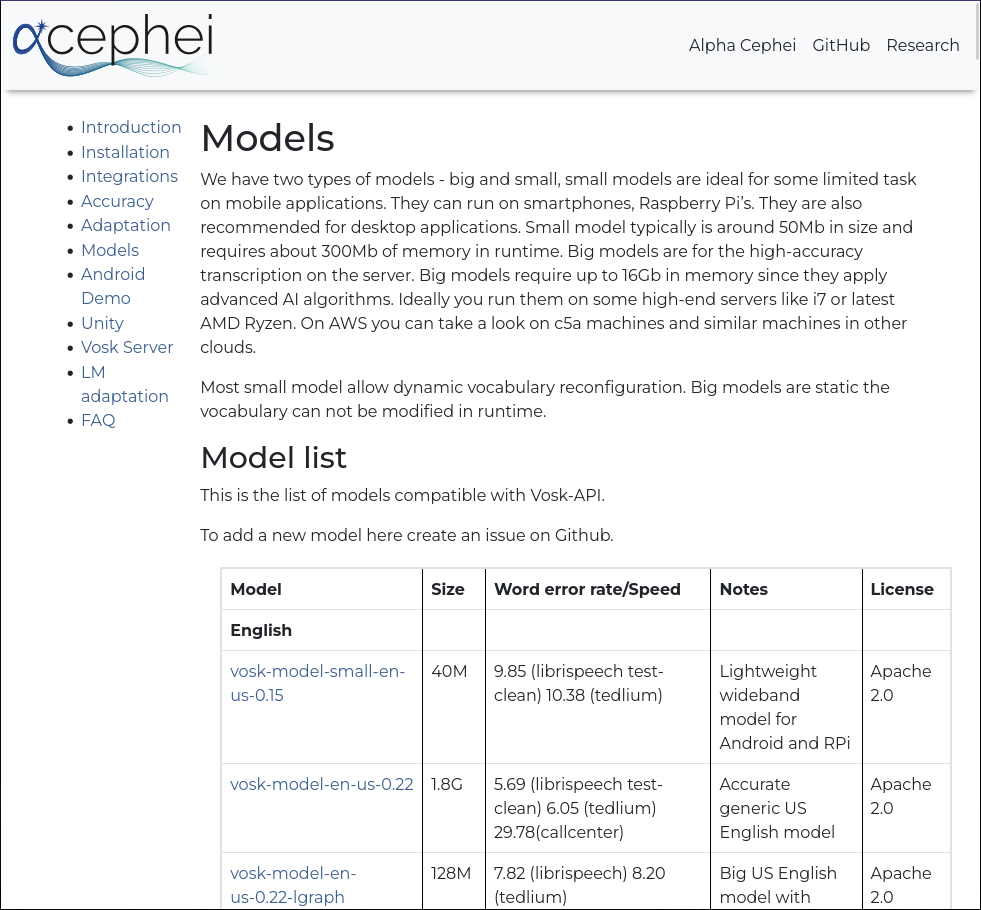
Спочатку вам слід отримати модель мовлення зі сторінки отримання даних alphacephei[1]. Перейдіть за посиланням (2) і отримайте потрібні вам моделі.
Типово, мовні моделі буде встановлено до таких тек:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
Якщо ви хочете скористатися певною текою, позначте Нетипова тека моделей (3) і вкажіть теку у текстовому полі нижче або натисніть  Відкрити вікно вибору файлів, щоб перейти до потрібної теки. Якщо ви використовуєте типову теку, її адресу буде показано у текстовому полі теки моделей для інформування.
Відкрити вікно вибору файлів, щоб перейти до потрібної теки. Якщо ви використовуєте типову теку, її адресу буде показано у текстовому полі теки моделей для інформування.
Якщо вами було встановлено VOSK у якійсь із попередніх версій Kdenlive, а у новій версії вибрано теку venv для Python, ви можете вилучити встановлені бібліотеки VOSK за допомогою такої команди у терміналі:
$ pip uninstall vosk srt
Натисніть кнопку Додати модель і введіть шлях до отриманих вами файлів.
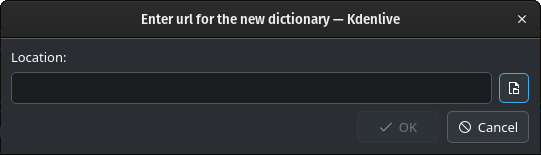
Натисніть кнопку Відкрити вікно вибору файлів, щоб відкрити програму для керування файлами вашої операційної системи, щоб перейти до місця, куди ви отримали файли, і вибрати файл моделі, який потрібно додати.
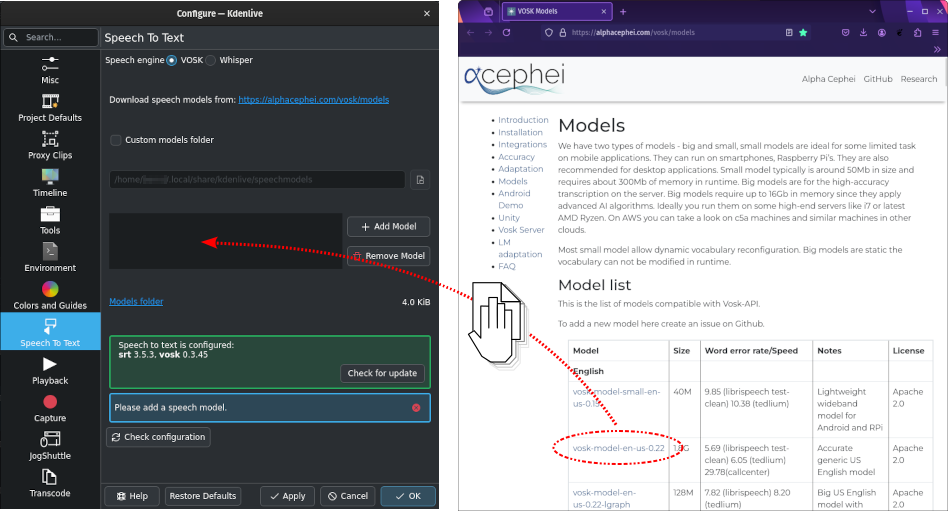
Крім того, можна перетягнути мовну модель зі сторінки отримання даних alphacephei[1] і скинути її до вікна моделей (4), і Kdenlive отримає дані і видобуде їх до типової теки або вказаної вами нетипової теки.
Примітка
Моделі є стиснутими файлами (.zip) і можуть мати розмір у декілька ГБ. Залежно від з’єднання з інтернетом отримання даних може бути досить тривалим. Після отримання файли слід розпакувати, що також може тривати досить довго, залежно від конфігурації вашої системи. Kdenlive не реагуватиме на команди, але працюватиме у фоновому режимі. Майте терпіння.
Після встановлення моделей Kdenlive покаже розмір теки моделей. Натисніть Тека моделей, щоб відкрити теку моделей за допомогою програми для керування файлами вашої операційної системи.
Whisper

Встановити потрібні залежності
Якщо ви перший раз перемикаєтеся на Whisper, вам доведеться спочатку встановити пропущені залежності (доведеться отримати близько 2 ГБ даних).
Після цього вам слід отримати одну або декілька моделей мовлення.
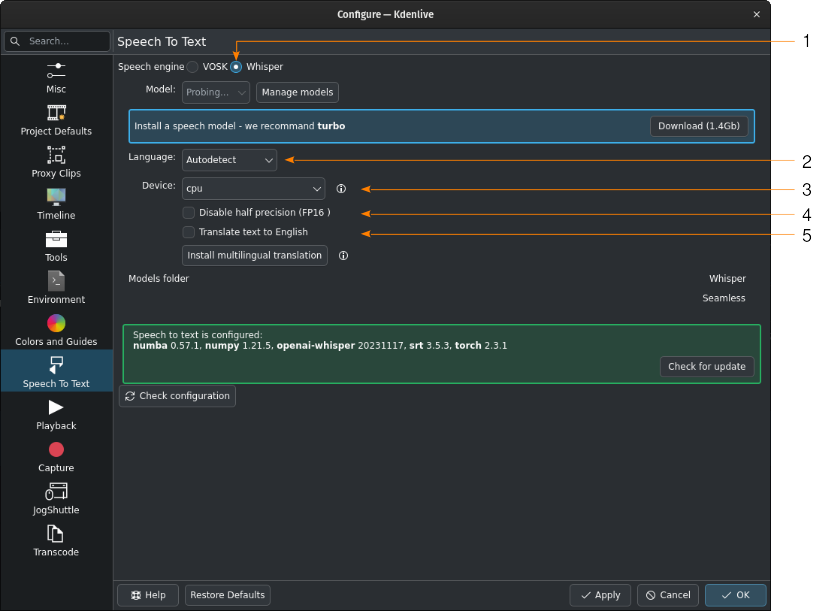
Whisper встановлено, але не отримано жодної моделі мовлення
- 1:
Whisper вибрано для розпізнавання мовлення
- 2:
Якщо не змінювати Автовиявлення, Kdenlive спробує визначити, яку мову слід використати для розпізнавання мовлення. Якщо це дає неправильні результати, виберіть тут належну мову.
- 3:
Ви можете перемикатися між використанням основного процесора і графічного процесора для розпізнавання мовлення. Для розпізнавання мовлення за допомогою графічного процесора потрібен графічний процесор із підтримкою CUDA.
- 4:
Тільки для графічних процесорів. Якщо Kdenlive виявляє графічну карту NVIDIA GTX 16xx, він автоматично вимикає половинну точність (FP16). Якщо у вас виникають проблеми з використанням графічного процесора, ви можете вимкнути половинну точність.
- 5:
Ви можете наказати Whisper перекласти текст англійською мовою. Якщо вам потрібен переклад іншими мовами, вам слід позначити пункт Встановити багатомовний переклад. Це надасть змогу увімкнути SeamlessM4T[2], а також отримати і встановити його моделі (приблизно 10 ГБ даних). Після цього обробка відбуватиметься в автономному режимі.
Натисніть Керувати моделями або перейдіть до рекомендації щодо використання турбо-моделі, натиснувши Отримати (1,4 ГБ). Більше відомостей щодо доступних моделей можна знайти на сторінці Whisper source code page.
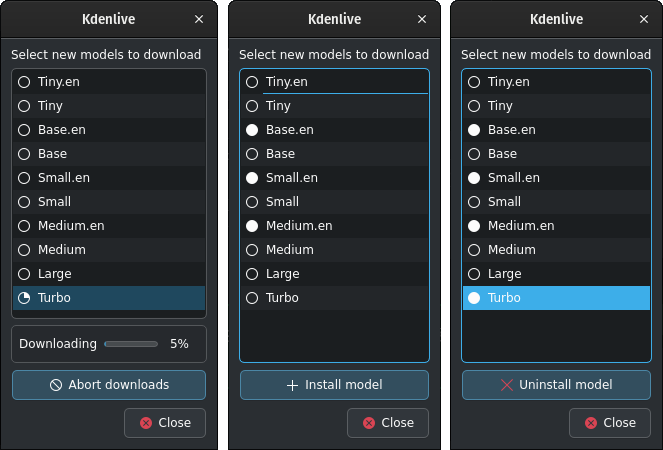
Отримання моделей Whisper і керування ними
Kdenlive показує процес отримання.
Для встановлених моделей мовлення буде показано зафарбований кружок. Ви можете вилучити модель натисканням кнопки Вилучити модель
Для доступних моделей буде показано порожній кружок. Ви можете встановити модель натисканням кнопки Встановити модель.
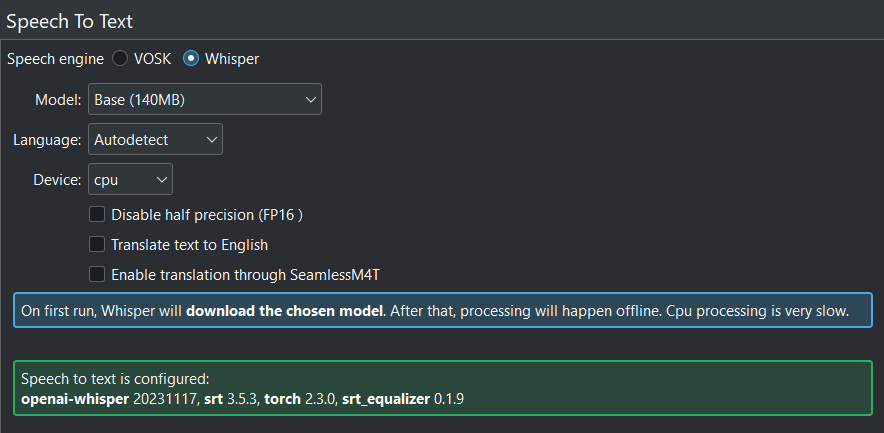
Якщо все налаштовано правильно, ви побачите таке вікно: усюди зелений!
Шлях, куди встановлено Whisper:
- Linux:
~/.local/share/kdenlive/venv/Lib- Windows:
%LocalAppData%\kdenlive\venv\Lib
Моделі мовлення Whisper зберігатимуться тут:
- Linux:
~/.local/share/kdenlive/opencvmodels- Windows:
%AppData%\kdenlive\opencvmodels
Щоб отримати дані та розпочати переклад субтитрів, виконайте ці кроки.
Виконати пошук оновлень можна натисканням кнопки Перевірити налаштування
Якщо вами було встановлено Whisper у якійсь із попередніх версій Kdenlive, а у новій версії вибрано теку venv для Python, ви можете вилучити встановлені бібліотеки Whisper за допомогою такої команди у терміналі:
$ pip uninstall openai-whisper
Примітка
Якщо під час розпізнавання мовлення ви отримуєте послідовні повідомлення про нестачу файлів моделі, перевірте, куди вас переведе натискання посилання поруч із текою моделей. Якщо це ~/.cache, де є тека Whisper, що містить усі моделі, які ви отримали, просто скопіюйте цю теку туди, де в повідомленні про помилку зазначено, що їх немає (найімовірніше: :file: ~/.var/app/org.kde.kdenlive/cache)
Виявлення об’єктів
На момент першого використання виявлення об’єктів має бути встановлено додаток.
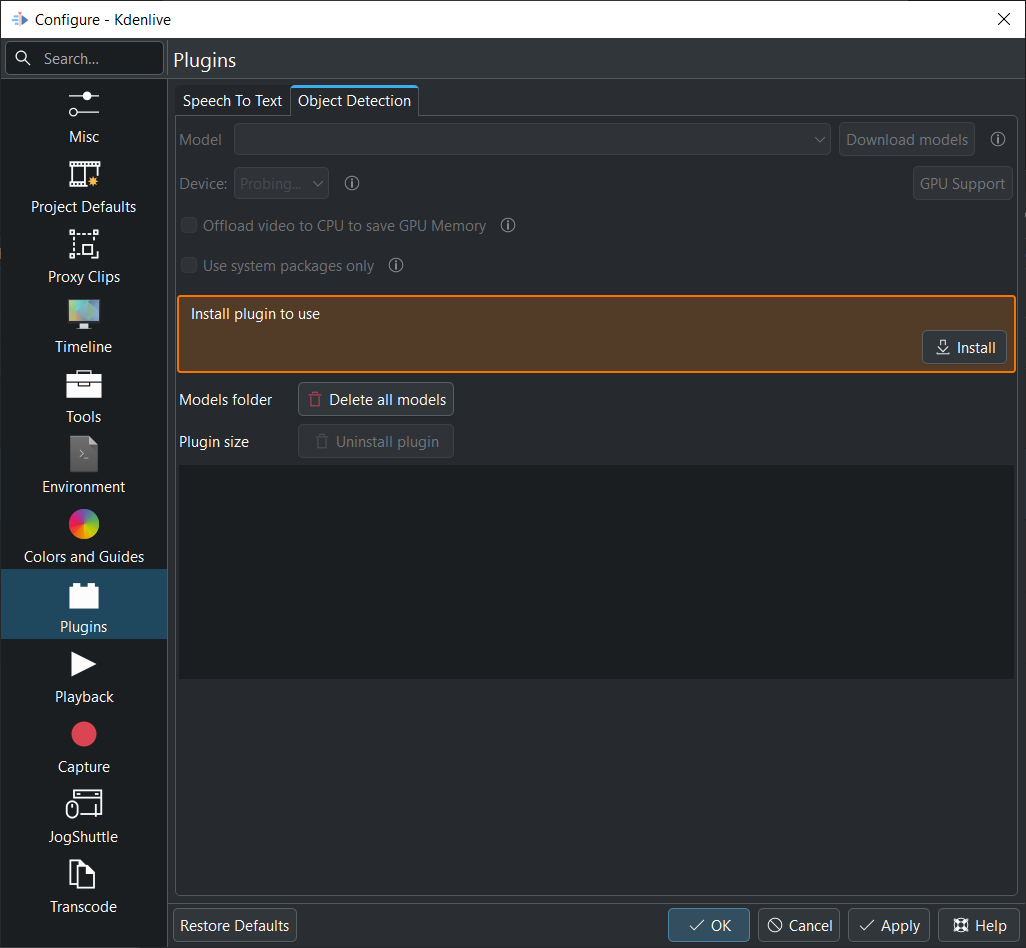
Додаток буде встановлено до такої теки:
- Linux:
~/.local/share/kdenlive/venv-sam- Windows:
%LocalAppData%\kdenlive\venv-sam
Якщо все встановлено належним чином, має виглядати якось так:
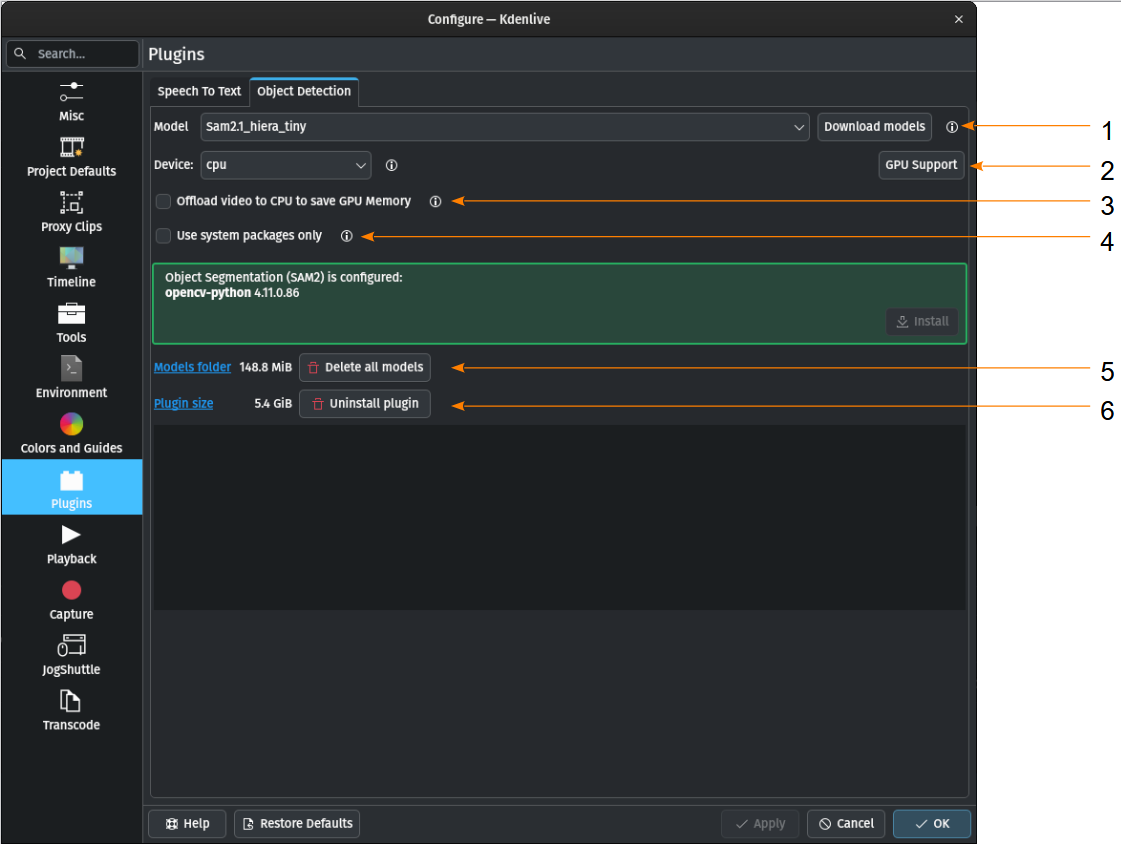
Якщо все налаштовано правильно, ви побачите таке вікно: усюди зелений!
- 1:
Модель — ви можете отримати різні моделі для виявлення об’єктів.
- 2:
Пристрій — ви можете перемикатися між використанням ЦП або ГП для виявлення об’єктів. Для виявлення об’єктів на графічному процесорі потрібен графічний процесор з підтримкою CUDA. Kdenlive автоматично намагається знайти вашу відеокартку. Якщо для вашої відеокартки передбачено підтримку CUDA (ГП Nvidia), вона встановить необхідний драйвер, щоб ви могли її використовувати. Якщо ваша відеокартка не підтримує CUDA або не виявляється Kdenlive, ви побачите лише центральний процесор. Підтримка ГП — якщо вашого ГП Nvidia немає у списку, спробуйте встановити альтернативу, виконавши ці кроки.
- 3:
Вивантажити відео до основного процесора і заощадити пам’ять графічного — якщо ви працюєте з довгими кліпами, у яких Kdenlive має виявити об’єкти, може статися аварійне завершення роботи програми. Якщо позначити цей пункт, програма вивантажить частину даних до оперативної пам’яті і розвантажить пам’ять графічного процесора.
- 4:
Використовувати лише загальносистемні пакунки — Якщо позначено, Kdenlive використовуватиме версію SAM2, яку встановлено у вашій системі. Лише для досвідчених користувачів, оскільки доведеться належним чином налаштувати усе власноруч.
- 5:
Тека моделей — у відповідь на натискання посилання буде відкрито теку, де зберігаються моделі SAM2 із зазначенням об’єму цієї теки. Натискання кнопки Вилучити усі моделі призведе до вилучення усіх даних з теки моделей.
- 6:
Розмір додатка — у відповідь на натискання посилання буде відкрито теку, де зберігаються скрипти venv-sam мовою Python із зазначенням об’єму даних, що зберігаються у теці. У відповідь на натискання кнопки Вилучити додаток venv-sam Python буде вилучено.
Встановлення підтримки графічного процесора вручну
Якщо Kdenlive не вдається виявити ваш графічний процесор NVIDIA автоматично, ви можете спробувати встановити його вручну.
Прискорення за допомогою графічного процесора працює лише з CUDA (Compute Unified Device Architecture), тобто закритої архітектури паралельних обчислень NVIDIA.
Перевірте версію встановленої CUDA:
відкрийте командну оболонку (Windows: Windows+R, введіть cmd і натисніть Enter)
Введіть команду nvidia-smi –-version
У вас має бути щось таке:
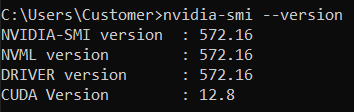
Тут версією CUDA є 12.8
Тепер натисніть Підтримка графічного процесора
Ви можете вибрати версію CUDA, яка є рівною тій, яку виявлено, або меншою за неї
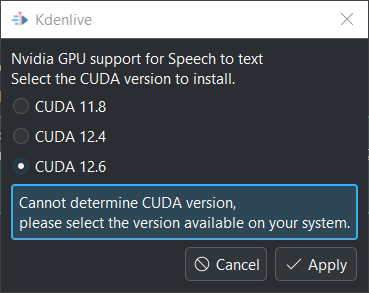
Виберіть версію CUDA, яка є меншою за ту, яку виявлено.
Натисніть кнопку Застосувати
У наступному вікні натисніть кнопку Продовжити
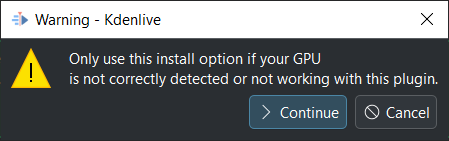
Kdenlive починає отримувати усі потрібні файли для використання графічного процесора. Щойно процедуру буде завершено, ви маєте побачити ваш графічний процесор у списку Пристрій, ось так:
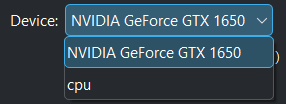
Підтримку графічного процесора успішно встановлено