Voz a texto
Advertencia
La conversión de voz a texto no funciona con la versión 21.04.2 de Kdenlive, debido a inconvenientes con la API de Vosk. Usar la versión 21.04.1 o 21.04.3 o posteriores.
Antes de poder usarse la conversión de Voz a texto, deberá ser configurada correctamente, instalando los modelos de lenguaje. Referirse a la sección Configuración de voz a texto del manual.
Consejo
Si bien es posible configurar ambos, VOSK y Whisper, para el reconocimiento de voz, el motor usado la próxima vez que se use esta característica, será el seleccionado en la sección de configuración de Complementos. Será posible cambiar de un método al otro durante el proceso de edición, por supuesto, pudiéndose usar distintos motores para diferentes propósitos. El panel Editor de voz contiene una opción para acceder directamente a la sección de la configuración de Complementos.
Reconocimiento de voz
Existen dos casos para el uso de reconocimiento de voz:
Creación automática de subtítulos
Creación de transcripciones con la habilidad de agregar clips a la Línea de tiempo basándose en la transcripción
Creación de subtítulos usando reconocimiento de voz de VOSK
Si aún no hubiera sido creada de antemano, agregar una pista de subtítulos haciendo clic en el botón  Editar subtítulos en la Barra de herramientas de la Línea de tiempo (6).
Editar subtítulos en la Barra de herramientas de la Línea de tiempo (6).
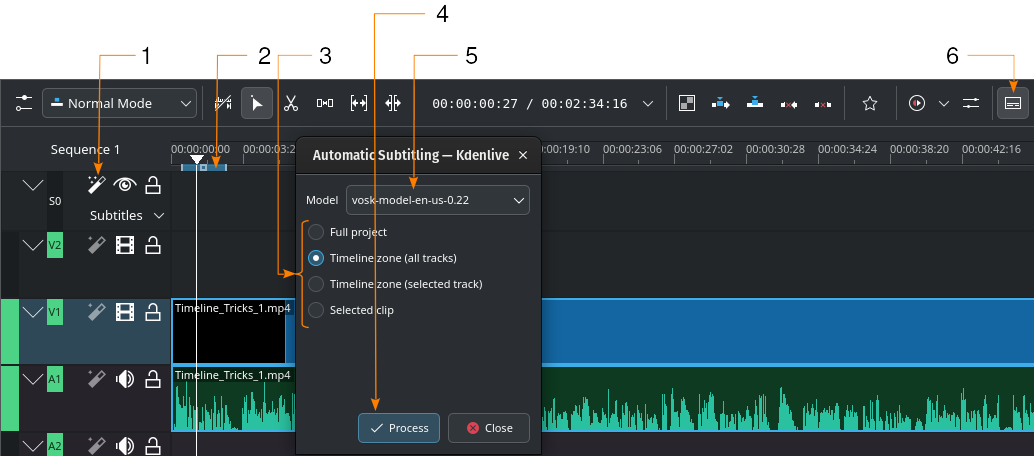
Generación automática de subtítulos usando el motor VOSK
- 1:
 Reconocimiento de voz. Hacer clic aquí para abrir la ventana Subtitulado automático.
Reconocimiento de voz. Hacer clic aquí para abrir la ventana Subtitulado automático.- 2:
Zona de la Línea de tiempo. Más detalles acerca de las Zonas de la Línea de tiempo podrán ser encontradas en la sección Regla de tiempo.
- 3:
Escoger qué parte de la línea de tiempo deberá ser usada para el reconocimiento de voz
- 4:
Procesar. Hacer clic para iniciar el reconocimiento
- 5:
Modelo. Permitirá seleccionar el modelo para el idioma de los subtítulos. Será posible instalar más modelos en la sección Complementos de la configuración.
- 6:
- Editar subtítulos. Hacer clic para alternar la visualización de la pista de subtítulos.
Pasos para la creación de subtítulos usando el reconocimiento de voz de VOSK
(los números entre paréntesis indicarán un elemento de la interfaz, tal como se identifica en la captura de pantalla de más arriba):
- Reconocimiento de voz (1). Hacer clic aquí para abrir la ventana de Subtitulado automático.
En caso de ser necesario, definir una zona en la Línea de tiempo (2) para la cual se desee realizar el reconocimiento de voz. Más detalles acerca de las Zonas de la Línea de tiempo podrán ser encontradas en la sección Regla de tiempo.
Modelo (5). Seleccionar el modelo para el idioma de los subtítulos. Será posible instalar más modelos en la sección Complementos de la Configuración.
Escoger qué parte de la línea de tiempo deberá ser usada para el reconocimiento de voz (3)
Procesar (4). Hacer clic para iniciar la creación de los subtítulos.
Los subtítulos serán creados e insertados de manera automática.
Nota sobre el paso 4: De forma predeterminada se analizará solo la Zona de la línea de tiempo (todas las pistas) (2 en la captura de arriba). Establecer la zona al área que se desee analizar (usar los atajos I y O para determinar los puntos de entrada y salida). La opción Clip seleccionado permitirá analizar únicamente el clip seleccionado.
Creación de subtítulos usando reconocimiento de voz de WHISPER
Si aún no hubiera sido creada de antemano, agregar una pista de subtítulos haciendo clic en el botón Editar subtítulos en la Barra de herramientas de la Línea de tiempo (10).
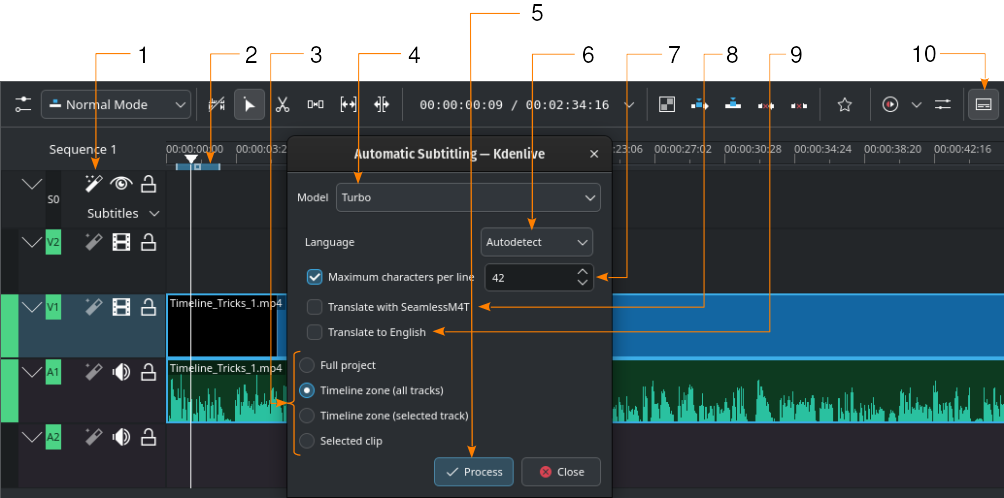
Generación automática de subtítulos usando el motor Whisper
- 1:
- Reconocimiento de voz. Hacer clic aquí para abrir la ventana Subtitulado automático.
- 2:
Zona de la Línea de tiempo. Más detalles acerca de las Zonas de la Línea de tiempo podrán ser encontradas en la sección Regla de tiempo.
- 3:
Escoger qué parte de la línea de tiempo deberá ser usada para el reconocimiento de voz
- 4:
Modelo. Permitirá seleccionar el modelo para el idioma de los subtítulos. Será posible instalar más modelos en la sección Complementos de la configuración.
- 5:
Procesar. Hacer clic para iniciar el reconocimiento
- 6:
Idioma. De forma predeterminada será Detección automática. Cambiar al idioma deseado, en caso de que la detección automática no funcionara correctamente.
- 7:
Máximo de caracteres por línea. Permitirá definir cuántos caracteres por línea se permitirán antes de que se inserte un salto de línea.
- 8:
Traducir mediante SeamlessM4T. Al activar esta opción se habilitarán dos campos adicionales de selección: Uno para el Idioma original y uno para el Idioma final. Esto también requerirá que la traducción mediante SeamlessM4T se encuentre activa en las preferencias (). Ver la sección sobre Complementos.
- 9:
Traducir al inglés. Activar esta opción para usar Whisper para que traduzca a inglés.
- 10:
- Editar subtítulos. Hacer clic para alternar la visualización de la pista de subtítulos.
Pasos para la creación de subtítulos usando el reconocimiento de voz de VOSK
(los números entre paréntesis indicarán un elemento de la interfaz, tal como se identifica en la captura de pantalla de más arriba):
- Reconocimiento de voz (1). Hacer clic aquí para abrir la ventana de Subtitulado automático.
En caso de ser necesario, definir una zona en la Línea de tiempo (2) para la cual se desee realizar el reconocimiento de voz. Más detalles acerca de las Zonas de la Línea de tiempo podrán ser encontradas en la sección Regla de tiempo.
Modelo (5). Seleccionar el modelo para el idioma de los subtítulos. Será posible instalar más modelos en la sección Complementos de la Configuración.
Escoger qué parte de la línea de tiempo deberá ser usada para el reconocimiento de voz (3)
Procesar (4). Hacer clic para iniciar la creación de los subtítulos.
Los subtítulos serán creados e insertados de manera automática.
Nota sobre el paso 4: De forma predeterminada se analizará solo la Zona de la línea de tiempo (todas las pistas) (2 en la captura de arriba). Establecer la zona al área que se desee analizar (usar los atajos I y O para determinar los puntos de entrada y salida). La opción Clip seleccionado permitirá analizar únicamente el clip seleccionado.
Traducción con SeamlessM4T
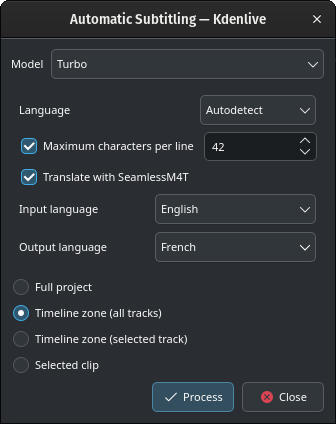
Traduciendo con SeamlessM4T
Seleccionar el Idioma original y el Idioma final y hacer clic en el botón Procesar.
Esto procesará el audio con Whisper, luego iniciará la traducción mediante SeamlessM4T. Es posible que la traducción llegue a ocupar el 100 % de la memoria RAM, 100 % de la CPU y 100 % del acceso a disco.
Atención
En caso de que el modelo de 9GB no hubiera sido descargado aún, será descargado en este momento. ¡A una velocidad de descarga de 100MB/s esto tomará aproximadamente 12 minutos!
Durante la descarga Kdenlive se comportará con normalidad. No hacer clic en Cerrar, ya que esto causará que la descarga sea abortada.
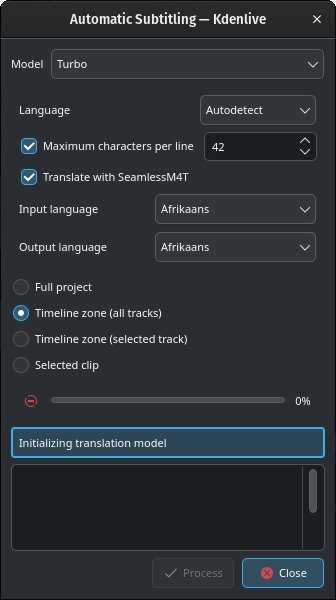
No debería causar preocupación ver un mensaje en el campo inferior como el siguiente: Initializando el modelo de traducción, durante el proceso de descarga.
Dependiendo de la velocidad de la conexión a internet, la descarga del modelo podría tomar bastante tiempo (cerca de 12 minutos a 100MB/s).
Una vez que el modelo de traducción hubiera sido descargado, comenzará la traducción.
Creación de clips usando reconocimiento de voz
Esta característica es útil durante entrevistas y otros tipos de material filmado en donde el diálogo resulte importante. Ir al panel Editor de voz. En caso de no estar visible, podrá activarse mediante la opción .
Nota
El uso de reconocimiento de voz para crear transcripciones y clips a partir de ellas será solo posible para los clips de la Bandeja del proyecto.
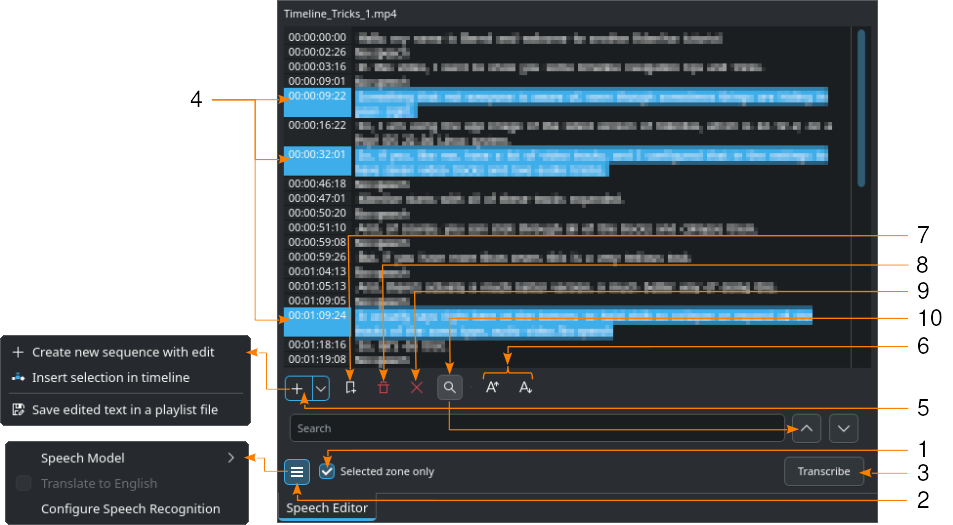
EL panel, mostrado aquí usando VOSK y con el cuadro de Búsqueda activo
Seleccionar un clip en la Bandeja del proyecto.
- 1:
Si fuera necesario, definir puntos de entrada y salida en el Monitor de clips y activar la opción Solo zona seleccionada. Esto únicamente transcribirá el texto dentro de esa zona.
- 2:
Hacer clic en el
 menú hamburguesa y escoger el modelo correcto para el idioma, cuando el motor VOSK esté seleccionado para el reconocimiento de voz. En caso de que esté seleccionado el motor Whisper, será posible seleccionar Traducir a inglés, si fuera necesario. El motor de reconocimiento de voz podrá ser seleccionado en . Hacer clic en Configurar reconocimiento de voz para abrir la sección de configuración de Voz a texto. Para más detalles acerca de su configuración ver la sección Configuración de Complementos.
menú hamburguesa y escoger el modelo correcto para el idioma, cuando el motor VOSK esté seleccionado para el reconocimiento de voz. En caso de que esté seleccionado el motor Whisper, será posible seleccionar Traducir a inglés, si fuera necesario. El motor de reconocimiento de voz podrá ser seleccionado en . Hacer clic en Configurar reconocimiento de voz para abrir la sección de configuración de Voz a texto. Para más detalles acerca de su configuración ver la sección Configuración de Complementos.- 3:
Presionar el botón Transcribir.
- 4:
Seleccionar el texto deseado. Mantener pulsadas las teclas CTRL o Mayús para seleccionar varios textos.
- 5:
Crear nueva secuencia con edición de texto creará una nueva secuencia con cada texto en un tiempo, como un clip independiente. Insertar selección en línea de tiempo creará clips para cada texto en un tiempo seleccionado, comenzando a partir de la posición del Cursor de tiempo. Guardar texto editado en una lista de reproducción creará un recurso en la Bandeja del proyecto con la totalidad del texto transcripto.
- 6:
 Aumentar tamaño de tipografía y
Aumentar tamaño de tipografía y  Disminuir tamaño de tipografía, aumentarán o disminuirán respectivamente el tamaño de la tipografía usada para mostrar el texto transcripto.
Disminuir tamaño de tipografía, aumentarán o disminuirán respectivamente el tamaño de la tipografía usada para mostrar el texto transcripto.- 7:
 Agregar marcador para la selección actual agregará un marcador en el tiempo del texto seleccionado. Más detalles acerca de los Marcadores de secuencia y los Marcadores está disponible en la sección Marcadores de secuencia.
Agregar marcador para la selección actual agregará un marcador en el tiempo del texto seleccionado. Más detalles acerca de los Marcadores de secuencia y los Marcadores está disponible en la sección Marcadores de secuencia.- 8:
 Borrar texto seleccionado borrará el texto seleccionado.
Borrar texto seleccionado borrará el texto seleccionado.- 9:
Eliminar zonas sin voz borrará todas las entradas marcadas como «Sin voz».
- 10:
 Buscar en texto alternará la visualización del campo de búsqueda. Allí será posible introducir cualquier texto que se desee buscar, dentro del texto transcripto. La búsqueda no es sensible a mayúsculas/minúsculas y encontrará cualquier ocurrencia de la cadena, aún dentro de palabras.
Buscar en texto alternará la visualización del campo de búsqueda. Allí será posible introducir cualquier texto que se desee buscar, dentro del texto transcripto. La búsqueda no es sensible a mayúsculas/minúsculas y encontrará cualquier ocurrencia de la cadena, aún dentro de palabras.  y
y  permitirán navegar por los textos resultantes de la búsqueda. En caso de que el campo de búsqueda se tornara rojo, será un indicativo de que se ha alcanzado la última ocurrencia de la búsqueda.
permitirán navegar por los textos resultantes de la búsqueda. En caso de que el campo de búsqueda se tornara rojo, será un indicativo de que se ha alcanzado la última ocurrencia de la búsqueda.
Detección de silencios
Nota
Esta característica solo funciona al usar el motor VOSK.
Seleccionar el clip en la Bandeja del proyecto y abrir el panel Editor de voz () .
Hacer clic en el menú hamburguesa y elegir el modelo apropiado para el idioma. En caso de que el modelo apropiado no se encontrara en la lista, hacer clic en Configurar reconocimiento de voz. Par más detalles acerca de cómo agregar modelos para el motor VOSK referirse al capítulo sobre Complementos.
Luego, hacer clic en el botón Transcribir.
Una vez hecho esto, escoger en el punto 9 (de más arriba) para Eliminar las zonas sin voz en una única operación. O hacer clic sobre el código de tiempo en donde se indique «Sin voz» (mantener pulsada Ctrl para seleccionar varios elementos) y simplemente pulsar la tecla Supr.
Repetir la operación para todas las partes que se deseen eliminar, incluyendo aquellas partes en donde alguien pronuncie palabras que no se desee incluir en la edición final.
Una vez finalizado, asegurarse de que la opción Solo zona seleccionada se encuentre inactiva, hacer clic en el botón Guardar texto editado en una lista de reproducción (en el punto 5 de la imagen de arriba) y luego de algunos segundos se agregará una nueva lista de reproducción a la Bandeja del proyecto sin silencios y sin los textos no deseados.