Spraak naar tekst
Waarschuwing
Spraak naar tekst werkt niet met versie 21.04.2 vanwege problemen met Vosk API. Gebruik versie 21.04.1 of 21.04.3 en latere versies.
Voordat u Spraak-naar-tekst kunt gebruiken, moet het eerst correct geconfigureerd worden en de spraakmodellen geïnstalleerd. Kijk in het hoofdstuk over Spraak naar tekst configureren.
Hint
Ofschoon zowel VOSK als Whisper voor de spraakherkenning kunnen worden geconfigureerd en ingesteld, zal de engine die is geselecteerd in de Spraak naar tekst configuratie-sectie de volgende keer dat deze functionaliteit word opgestart voor de spraakherkenning worden gebruikt. Tijdens het bewerken kan natuurlijk tussen deze heen en weer worden geschakeld, en voor andere doeleinden andere engines gebruikt worden. De Spraak-Editor widget heeft een menu-item om makkelijk de configuratie-sectie te openen zonder de route Spraak naar tekst te volgen.
Spraakherkenning
Er zijn twee manieren waarop spraakherkenning gebruikt wordt:
Ondertitels automatisch creëren
Het creëren van transcripties en de mogelijkheid om clips aan de tijdlijn toe te voegen gebaseerd op het transcriptie
Ondertiteling aanmaken met gebruik van VOSK-spraakherkenning
Creëer een ondertiteltrack als deze nog niet aanwezig is door te klikken op de  Hulpmiddel voor ondertitels bewerken icon in de tijdlijnwerkbalk (6).
Hulpmiddel voor ondertitels bewerken icon in de tijdlijnwerkbalk (6).
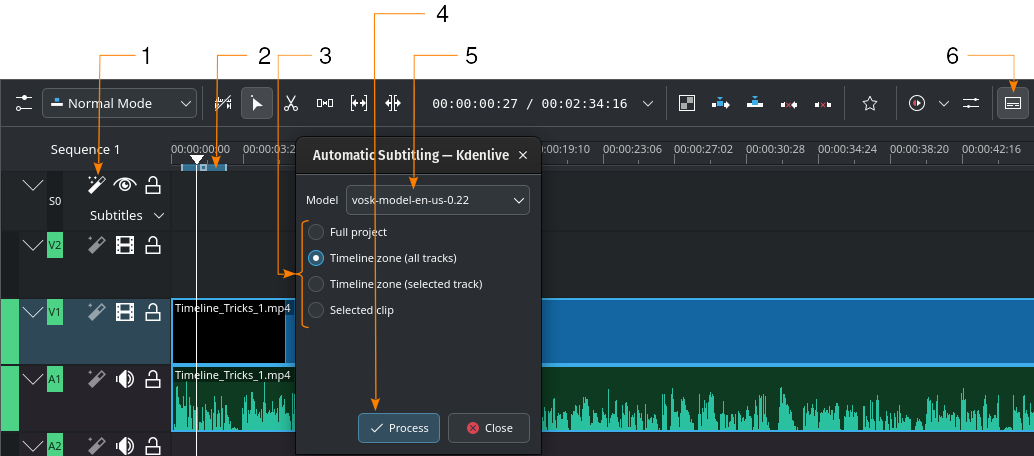
Automatische generatie van ondertitels met de hulp van de VOSK engine
- 1:
 Spraakherkenning. Klik hier om het dialoogvenster Automatische ondertiteling te openen.
Spraakherkenning. Klik hier om het dialoogvenster Automatische ondertiteling te openen.- 2:
Tijdlijnzone. Meer informatie over Tijdlijnzones is te vinden in het hoofdstuk Tijdlijnliniaal.
- 3:
Kies welk deel van de tijdlijn gebruikt zou moeten worden voor spraakherkenning
- 4:
Proces, Klik om de herkenning te starten
- 5:
Model. Selecteer het model voor de taal in de ondertitels. In de Configuratie sectie Spraak naar tekst kunnen extra modellen geïnstalleerd worden.
- 6:
- Hulpmiddel voor ondertitels bewerken. Klik om de ondertiteltrack te openen of te sluiten.
Stappen voor de creatie van ondertiteling met gebruik van VOSK-spraakherkenning
(de nummers tussen haakjes verwijzen naar het GUI element in de schermafdruk hierboven):
- Spraakherkenning (1). Klik hier om het dialoogvenster Automatische ondertiteling te openen.
Definieer indien nodig een tijdlijnzone (2) waarvoor u de spraakherkenning wilt gebruiken. Meer informatie over Tijdlijnzones is te vinden in het hoofdstuk Tijdlijnliniaal.
Model (5). Selecteer het model voor de taal in de ondertitels. In de Configuratie sectie Spraak naar tekst kunnen extra modellen geïnstalleerd worden.
Kies welk deel van de tijdlijn toegepast zou moeten worden voor de spraakherkenning (3)
Verwerken (4). Klik om de creatie van de ondertitels te starten.
De ondertitel is gecreëerd en automatisch ingevoegd.
Opmerking bij stap 4: de standaard is om alleen de tijdlijnzone (alle tracks) (2 in de schermafdruk hierboven). te analyseren. Stel de zone in in de tijdlijn op wat u wilt analyseren (gebruik I en O om in- en uitpunten in te stellen). Optie Geselecteerde clips analyseert alleen de geselecteerde clip.
Ondertiteling aanmaken met gebruik van WHISPER-spraakherkenning
Creëer een ondertiteltrack als deze nog niet aanwezig is door te klikken op de Hulpmiddel voor ondertitels bewerken icon in de tijdlijnwerkbalk (11).
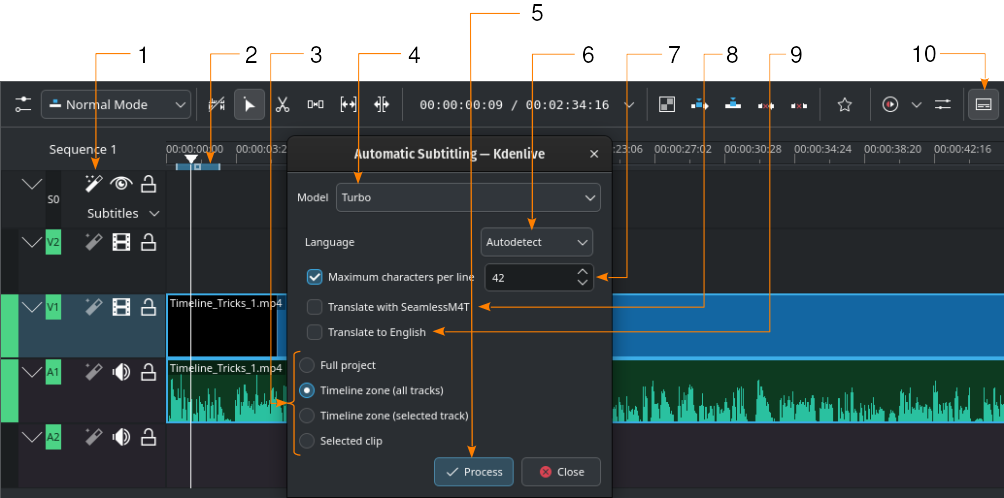
Automatische generatie van ondertitels met de hulp van de Whisper engine
- 1:
- Spraakherkenning. Klik hier om het dialoogvenster Automatische ondertiteling te openen.
- 2:
Tijdlijnzone. Meer informatie over Tijdlijnzones is te vinden in het hoofdstuk Tijdlijnliniaal.
- 3:
Kies welk deel van de tijdlijn gebruikt zou moeten worden voor spraakherkenning
- 4:
Model. Selecteer het model voor de taal in de ondertitels. In de Configuratie sectie Spraak naar tekst kunnen extra modellen geïnstalleerd worden.
- 5:
Proces, Klik om de herkenning te starten
- 6:
Taal . De standaard is Automatisch detecteren. Selecteer de juiste taal als deze juist is gedetecteerd.
- 7:
Maximum tekens per regel . Definieert het aantal tekens dat per regel toegestaan is voordat een regelafbreking wordt toegepast.
- 8:
Vertalen met SeamlessM4T. Als dit wordt geselecteerd dan komen twee extra velden beschikbaar: een voor de Invoertaal, en een voor de Uitvoertaal. Om dit te gebruiken is het wel noodzakelijk dat vertaling met SeamlessM4T is ingeschakeld in de instellingen ( Spraak naar tekst). Kijk in het hoofdstuk over Spraak naar tekst configureren.
- 9:
Naar Engels vertalen. Selecteer deze om Whisper te gebruiken voor de vertaling naar Engels.
- 10:
- Hulpmiddel voor ondertitels bewerken. Klik om de ondertiteltrack te openen of te sluiten.
Stappen voor de creatie van ondertiteling met gebruik van VOSK-spraakherkenning
(de nummers tussen haakjes verwijzen naar het GUI element in de schermafdruk hierboven):
- Spraakherkenning (1). Klik hier om het dialoogvenster Automatische ondertiteling te openen.
Definieer indien nodig een tijdlijnzone (2) waarvoor u de spraakherkenning wilt gebruiken. Meer informatie over Tijdlijnzones is te vinden in het hoofdstuk Tijdlijnliniaal.
Model (5). Selecteer het model voor de taal in de ondertitels. In de Configuratie sectie Spraak naar tekst kunnen extra modellen geïnstalleerd worden.
Kies welk deel van de tijdlijn toegepast zou moeten worden voor de spraakherkenning (3)
Verwerken (4). Klik om de creatie van de ondertitels te starten.
De ondertitel is gecreëerd en automatisch ingevoegd.
Opmerking bij stap 4: de standaard is om alleen de tijdlijnzone (alle tracks) (2 in de schermafdruk hierboven). te analyseren. Stel de zone in in de tijdlijn op wat u wilt analyseren (gebruik I en O om in- en uitpunten in te stellen). Optie Geselecteerde clips analyseert alleen de geselecteerde clip.
Vertalen met SeamlessM4T
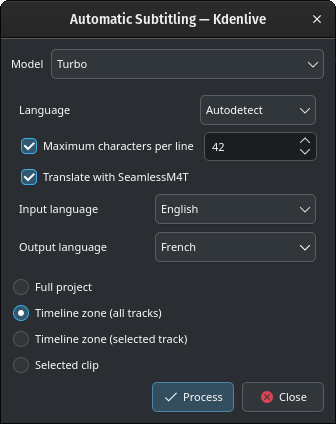
Het vertalen met SeamlessM4T
Selecteer Invoertaal en Uitvoertaal en klik op Verwerken.
Dit zal eerst de audio verwerken met whisper, daarna start de vertaling met SeamlessM4T. Vertaling kan 100% RAM, 100% CPU en 100% schijftoegang gebruiken.
Let op
Als het 9GB model nog niet is gedownload, zal het nu gedownload worden. Met een 100MB/s downloadsnelheid zal dit ongeveer 12 minuten duren!
Tijdens het downloaden zal Kdenlive normaal reageren. Klik niet op Sluiten anders wordt het downloaden gestopt.
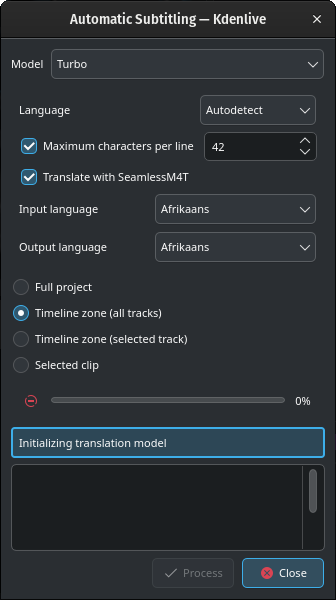
Wees niet ongerust als u zo’n bericht in het onderstaande vak ziet Vertaalmodel wordt geïnitialiseerd terwijl het downloaden actief is.
Afhankelijk van de internetverbinding en de bandbreedte, kan het downloaden van het model nogal wat tijd in beslag nemen (ongeveer 12 minutes met 100MB/s downloadsnelheid).
Als het vertaalmodel is gedownload, zal de vertaling starten.
Clips aanmaken met de hulp van spraakherkenning
Dit is nuttig voor interviews en andere spraakgerelateerde opnamen. Ga naar het spraak-bewerk-widget. Schakel het menu-item in als het nog niet ingeschakeld is.
Notitie
Transcripties aanmaken met de hulp van spraakherkenning en daarvan clips creëren, is alleen mogelijk met clips in de Project Bin.
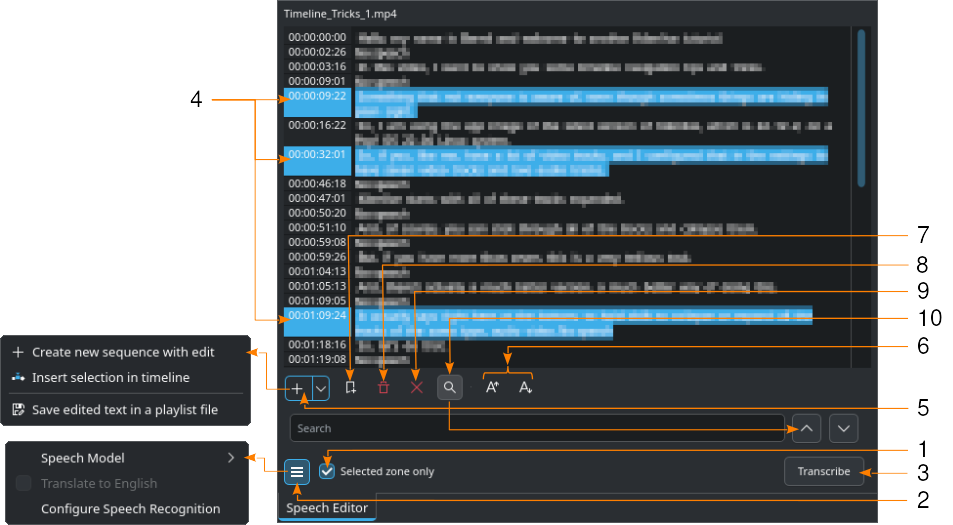
Getoond met de VOSK-engine en Zoeken (10) ingeschakeld
Selecteer een clip in de Project-bin.
- 1:
Indien nodig stel in/uitpunt in in de Clip Monitor en schakel keuzevak Alleen geselecteerde zone in. Dit zal alleen de tekst in de zone transcriberen (uitschrijven).
- 2:
Click on
 Hamburger Menu and choose the model for the correct language when the VOSK engine is set for speech recognition. If the Whisper engine is selected, you can select Translate to English if needed. You select the speech recognition engine in . Click on Configure Speech Recognition to open the configuration section for Speech to Text. For more details about the configuration refer to the chapter Configure Speech to Text.
Hamburger Menu and choose the model for the correct language when the VOSK engine is set for speech recognition. If the Whisper engine is selected, you can select Translate to English if needed. You select the speech recognition engine in . Click on Configure Speech Recognition to open the configuration section for Speech to Text. For more details about the configuration refer to the chapter Configure Speech to Text.- 3:
Druk op de knop Transcriberen
- 4:
Selecteer de tekst die u wilt. Hou CTRL of Shift ingedrukt om verschillende teksten te selecteren.
- 5:
Een nieuwe sequentie met bewerken aanmaken maakt een nieuwe sequentie aan met elke tijdcodetekst als een enkele clip. Voeg selectie in in de tijdlijn vanaf de positie van de afspeelkop. Bewerkte tekst opslaan in een afspeellijstbestand creëert een item in de project-bin met de gehele getranscribeerde (uitgeschreven) tekst.
- 6:
 Tekengrootte groter en
Tekengrootte groter en  Tekengrootte kleiner vergroot, respectievelijk, verkleint de lettergrootte.
Tekengrootte kleiner vergroot, respectievelijk, verkleint de lettergrootte.- 7:
 Markering toevoegen voegt een markering toe aan de tijdcode van de geselecteerde tekst. Meer informatie over Tijdlijnmarkeringen en Markeringen is te vinden in het hoofdstuk over Tijdlijnmarkeringen.
Markering toevoegen voegt een markering toe aan de tijdcode van de geselecteerde tekst. Meer informatie over Tijdlijnmarkeringen en Markeringen is te vinden in het hoofdstuk over Tijdlijnmarkeringen.- 8:
 Selectie verwijderen verwijdert de geselecteerde tekst.
Selectie verwijderen verwijdert de geselecteerde tekst.- 9:
Zones zonder spraak verwijderen verwijdert in een keer alle items “zonder spraak”.
- 10:
 In tekst zoeken schakelt het zoekveld in. Voer hier de tekst in die u wilt vinden in de getranscribeerde ( uitgeschreven) tekst. Het zoeken is niet hoofdletter gevoelig en zal dus alle plekken vinden waar de gezochte tekst voorkomt, zelfs in woorden. Met
In tekst zoeken schakelt het zoekveld in. Voer hier de tekst in die u wilt vinden in de getranscribeerde ( uitgeschreven) tekst. Het zoeken is niet hoofdletter gevoelig en zal dus alle plekken vinden waar de gezochte tekst voorkomt, zelfs in woorden. Met  en
en  navigeert u naar de volgende plek waar de gezochte tekst voorkomt. Als het zoekveld rood kleurt dan heeft u de laatste plek bereikt in de tekst waar de gezochte tekst voorkomt.
navigeert u naar de volgende plek waar de gezochte tekst voorkomt. Als het zoekveld rood kleurt dan heeft u de laatste plek bereikt in de tekst waar de gezochte tekst voorkomt.
Stiltedetectie
Notitie
Dit werkt alleen met de VOSK-engine.
Selecteer de clip in de Project Bin en open het spraakbewerker-venster () .
Klik op Hamburgermenu en selecteer het model voor uw taal. Als het juiste model niet in de lijst voorkomt, klik dan op Spraakherkenning configureren. Voor meer informatie over hoe modellen toe te voegen voor de VOSK engine verwijzen we u naar het hoofdstuk over Plug-ins.
Klik daarna knop Herkennen starten.
Nadat dit is gedaan, kies onder punt 6 bovenstaand Spraakzones verwijderen om dat in een keer te doen. Of klik op de tijdcode waar “Zonder spraak” is aangegeven (hou Ctrl in gedrukt om verschillende items in een keer te selecteren) en tik gewoon op de toets Delete.
Herhaal de bewerking voor alle delen die u wilt verwijderen, inclusief waar iemand iets zegt wat u niet wilt meenemen in uw uiteindelijke bewerking.
Nadat u klaar bent, ga na dat Alleen geselecteerde zone is uitgeschakeld, klik op de knop Bewerkte tekst opslaan in een afspeellijst (bovenstaand onder punt 5) en na enkele seconden wordt een nieuwe afspeellijst toegevoegd in de project-bin zonder stilte en zonder de tekst die u niet wilt.